一、 token的解析与生成
1. 概述
在爬取美团店铺数据的时候,相信很多伙伴都遇到了类似这样的情况:在网页的Console能够通过XPath获取到HTML元素的值,但是在爬虫脚本中使用XPath却无法拿到,这是因为美团在获取店铺数据时加了token验证。比如,在chrome浏览器打开美团首页,右键检查,随便点击一类美食,可以看到如下图的getPoiList接口调用:
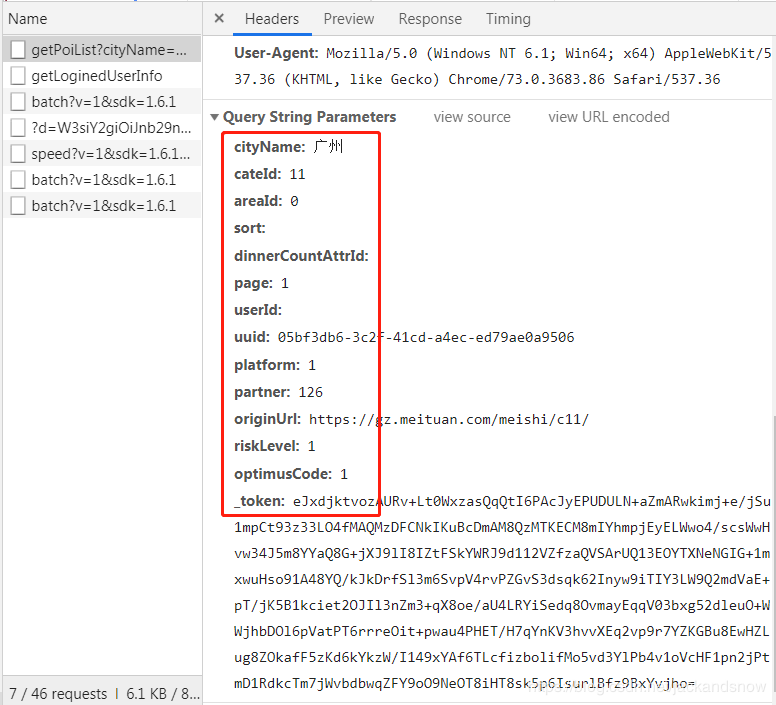
在上述图片中,可以看到调用getPoiList接口时传递了若干的参数,其中一个重要的就是token,美团后台为了防止爬虫,token是经过加密后生成的,而且每个token的有效时间是极其短暂的,所以正确解析token实现美团爬虫对很多人来说都是极其困难的。
2. token的解析
要想解析token,首先得弄清楚其使用的加密算法,而对于美团的token,加密算法其实比较简单,就是采用了二进制压缩与base64编码。所以解析token主要分为两个步骤:一是base64解码,二是二进制解压。解析token时主要用到了base64和zlib两个库,下面以实际例子来验证。
首先定义解析token方法:1
2
3
4
5
6def decode_token(token):
# base64解码
token_decode = base64.b64decode(token.encode())
# 二进制解压
token_string = zlib.decompress(token_decode)
return token_string
然后获取美团的多个token,调用decode_token方法进行解析:1
2
3
4
5
6
7
8
9
10
11if __name__ == '__main__':
token = [
'eJxVjstuqzAURf/F06LYxkAgUgeQ0MvzkoQ8QFUHbngnJgGcpKG6/35dqR1UOtLeZ501OJ+gdzMwwwgZCEnglvdgBvAETTQgAT6Ii6qqsqxPsUIMIoHDb6bIhgTe+90CzF4xwkiaqujti6wFeMWGjCSMdIF+uiK6rIj5slwhgYrzyzCDsBwnLK/5lbaTw5lB0YeqhgeMofgECJ1thC7y+J30O/nPHorXhTvUZSta7t2z5sij+2iuqiuMqyT3lDH961/cpPO5/7IZojDYtlraKOfij7JtjiFG8yGyya3cO0TLCiiXZtMG9+xkLi1rSM9r4sEqXch6Qcan5WXbMs9edilVt3ubIXYKrHUXxXSJu8bmL5auGLt8nXgqbntVM6N459ZGjGwSnIp4rGoe1h+Qre5Dn+3plG4e88ZtF0fM/KvR3iKHXuerfSf3FtRPtMvIIXmi2Q2N2chI+95somyc15phQmdlOlH0cGgRBszmflI+P4N//wEWi44a',
'eJxVjstuozAUht/F26LYBkxDpC4gocN1SEIuoGoWbsw1MQngJC1V372u1C5GOtJ/Od/i/wC9x8AMI2QipIBb3oMZwBM0MYACxCA/hBBVQwgjYmIFHP7vDGIq4LXfLcDsBcusPBL077tZy+IFmypSMJrK6tfr0qu6vG/KkxCohLgMMwjLccLzWlxpOzmcOZR+qGp4wBjKJUDifCNxqccfpT8qfnMkp0t2qMtWuty/s+Yo4vtoraorTKo09/Ux+xtcvLQLRPC8GeIo3LZG1ujn4o++bY4RRvMhdrRbuXc1gxVQLa2mDe/sZC1te8jOa82HVbZQp4U2Piwv25b7zrLLKNnuHY74KbTXXZzQJe4aRzzbU93c5evUJ7jtiWHFyc6rzQQ5WngqkrGqRVS/Qb66Dz3b00e6eZ83Xrs4Yh5czfYWu/Q6X+07tbfh9EQ7ph3SB8puaGQj19rXZhOzcV4bpgXdleXG8btLiyjkjgjS8ukJfH4B4qqN+w==',
'eJxdjktvozAURv+Lt0WxjYFCpC4gocNzSEIeoGoWbswzMQngJFNG89/HldrNSFf6vnvuWdw/YPAZmGOELIQUcC8GMAd4hmYGUIAY5UXXdZUg3USEmAo4/scsSwHvw34J5m8YYaQ86+jXJ9lI8IYtFSkYmRJ9d012VZPzaflSArUQ13EOYTXNeNGIG+1mxwuHso91A48YQ/kJkDrfSl3m6SvpV4rvPZavS3dsqk62Iniw9iSSx2Sv6xtM66wItCn/GV79rA9F+LodkzjadUbeapfyh7ZrTzFGizFxyb06eMRgJVQru+2iBzvbK8cZ88uGBLDOl6pZkulpdd11PHBXfU713cHliJ8jZ9MnKV3hvnXFq2Nq1r7YZIGOu0E37CTd+42VIpdE5zKd6kbEzW/I149xYAf6TLcfi9bvlifMw5vV3ROP3hbrQ68ODjTPtGfkmD1RdkcTmzjp3tttwqZFY1g29Na2lyQfHi3jiLsizKqXF/D3Hwp7jhM=',
'eJxdjktvozAURv+Lt0WxjYGESF1AQofnkIQ8QFUXbngndgI4yZTR/PdxpXZT6Urfd889i/sX9F4O5hghEyEF3IsezAGeoIkBFCAGedF1XSUIY4OougKOP5gxVcB7v1+C+StGGClTHb19ko0Er9hUkYLRTKLvrsmuanI+LU9KoBbiOswhrMYJKxpxo3xyvDAo+1A38IgxlJ8AqbOt1GWevpJ+pfjeI/m6dIem4rIV/iNvTyJ+jNa6vsGkTgtfG7PfwdVLu0AEL9shjsIdN7JWu5S/tF17ijBaDLFD7tXBJUZeQrWyWh4+8rO1su0hu2yID+tsqc5KMj6trjvOfGfVZVTfHRyG2Dm0N12c0BXuWke82DPN3Beb1Ncx73XDipO915gJckh4LpOxbkTU/IFs/Rj6/ECndPuxaD2+PGEW3Ex+j116W6wPndrbcHamXU6O6RPN72jMR0b4e7uN83HRGKYF3bXlxvGHS8soZI4I0ur5Gfz7D+r3jgA='
]
for i in range(0, len(token)):
token1 = decode_token(token[i])
print(token1)
最后解析后得到了以下的结果:1
2
3
4b'{"rId":100900,"ver":"1.0.6","ts":1555228714393,"cts":1555228714429,"brVD":[1010,750],"brR":[[1920,1080],[1920,1040],24,24],"bI":["https://gz.meituan.com/meishi/c11/",""],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwdjktOwzAQhu/ShXeJ4zYNKpIXqKtKFTsOMLUn6Yj4ofG4UjkM10CsOE3vgWH36df/2gAjnLwdlAPBBsYoR3J/hYD28f3z+PpUnmJEPqYa5UWEm0mlLBRqOSaP1qjEtFB849VeRXJ51nr56AOSVIi9S0E3LlfSzhitMix/mQwsrdWa7aTyCjInDk1mKu9nvOHauCQWq2rB/8laqd3cX+adv0zdzm3nbjTOdzCi69A/HQAHOOyHafMLmEtKXg=="}'
b'{"rId":100900,"ver":"1.0.6","ts":1555230010591,"cts":1555230010659,"brVD":[1010,750],"brR":[[1920,1080],[1920,1040],24,24],"bI":["https://gz.meituan.com/meishi/c11/",""],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwdjktOwzAQhu/ShXeJ4zYNKpIXqKtKFTsOMLUn6Yj4ofG4UjkM10CsOE3vgWH36df/2gAjnLwdlAPBBsYoR3J/hYD28f3z+PpUnmJEPqYa5UWEm0mlLBRqOSaP1qjEtFB849VeRXJ51nr56AOSVIi9S0E3LlfSzhitMix/mQwsrdWa7aTyCjInDk1mKu9nvOHauCQWq2rB/8laqd3cX+adv0zdzm3nbjTOdzCi69A/HQAHOOyHafMLmEtKXg=="}'
b'{"rId":100900,"ver":"1.0.6","ts":1555230580338,"cts":1555230580399,"brVD":[1010,750],"brR":[[1920,1080],[1920,1040],24,24],"bI":["https://gz.meituan.com/meishi/c11/",""],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwdjktOwzAQhu/ShXeJ4zYNKpIXqKtKFTsOMLUn6Yj4ofG4UjkM10CsOE3vgWH36df/2gAjnLwdlAPBBsYoR3J/hYD28f3z+PpUnmJEPqYa5UWEm0mlLBRqOSaP1qjEtFB849VeRXJ51nr56AOSVIi9S0E3LlfSzhitMix/mQwsrdWa7aTyCjInDk1mKu9nvOHauCQWq2rB/8laqd3cX+adv0zdzm3nbjTOdzCi69A/HQAHOOyHafMLmEtKXg=="}'
b'{"rId":100900,"ver":"1.0.6","ts":1555230116325,"cts":1555230116367,"brVD":[1010,750],"brR":[[1920,1080],[1920,1040],24,24],"bI":["https://gz.meituan.com/meishi/c11/",""],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwdjktOwzAQhu/ShXeJ4zYNKpIXqKtKFTsOMLUn6Yj4ofG4UjkM10CsOE3vgWH36df/2gAjnLwdlAPBBsYoR3J/hYD28f3z+PpUnmJEPqYa5UWEm0mlLBRqOSaP1qjEtFB849VeRXJ51nr56AOSVIi9S0E3LlfSzhitMix/mQwsrdWa7aTyCjInDk1mKu9nvOHauCQWq2rB/8laqd3cX+adv0zdzm3nbjTOdzCi69A/HQAHOOyHafMLmEtKXg=="}'
3. token的生成
在上一步解析token的结果中,可以看到token中包含有以下几个信息,而且除了ts和cts两个属性值外,其余值都是固定的。1
2
3
4
5
6
7
8
9
10
11
12
13"rId":100900,
"ver":"1.0.6",
"ts":1555228714393,
"cts":1555228714429,
"brVD":[1010,750],
"brR":[[1920,1080],[1920,1040],24,24],
"bI":["https://gz.meituan.com/meishi/c11/",""],
"mT":[],
"kT":[],
"aT":[],
"tT":[],
"aM":"",
"sign":"eJwdjktOwzAQhu/ShXeJ4zYNKpIXqKtKFTsOMLUn6Yj4ofG4UjkM10CsOE3vgWH36df/2gAjnLwdlAPBBsYoR3J/hYD28f3z+PpUnmJEPqYa5UWEm0mlLBRqOSaP1qjEtFB849VeRXJ51nr56AOSVIi9S0E3LlfSzhitMix/mQwsrdWa7aTyCjInDk1mKu9nvOHauCQWq2rB/8laqd3cX+adv0zdzm3nbjTOdzCi69A/HQAHOOyHafMLmEtKXg=="
ts和cts两个值都是时间戳,其实就是token的有效时间,所以我们在生成token时主要修改这两个属性,其余值保持不变即可。但是要注意到这里的ts和cts是我们传统时间戳的1000倍,所以生成的时候千万不要忘记扩大1000倍。废话不多说,直接看代码吧。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# 生成token
def encode_token():
ts = int(datetime.now().timestamp() * 1000)
token_dict = {
'rId': 100900,
'ver': '1.0.6',
'ts': ts,
'cts': ts + 100 * 1000,
'brVD': [1010, 750],
'brR': [[1920, 1080], [1920, 1040], 24, 24],
'bI': ['https://gz.meituan.com/meishi/c11/', ''],
'mT': [],
'kT': [],
'aT': [],
'tT': [],
'aM': '',
'sign': 'eJwdjktOwzAQhu/ShXeJ4zYNKpIXqKtKFTsOMLUn6Yj4ofG4UjkM10CsOE3vgWH36df/2gAjnLwdlAPBBsYoR3J/hYD28f3z+PpUnmJEPqYa5UWEm0mlLBRqOSaP1qjEtFB849VeRXJ51nr56AOSVIi9S0E3LlfSzhitMix/mQwsrdWa7aTyCjInDk1mKu9nvOHauCQWq2rB/8laqd3cX+adv0zdzm3nbjTOdzCi69A/HQAHOOyHafMLmEtKXg=='
}
# 二进制编码
encode = str(token_dict).encode()
# 二进制压缩
compress = zlib.compress(encode)
# base64编码
b_encode = base64.b64encode(compress)
# 转为字符串
token = str(b_encode, encoding='utf-8')
return token
生成token其实就是解析token的逆过程,所以要先进行二进制压缩,然后进行base64编码,最后转为字符串,下面就是生成了4个token的结果。1
2
3
4eJxNUMtuo0AQ/BXfOCTyzABDIFIOYJPwDLbxAxTlMDFve8YGxnbCav99mV1tdg8tVXVXV0n1QzqspcfJ2/v9RProVgK+IUOG9xMEdThuv5kqmKyKEeLOzUYxgtCA41na815QjLFsaBiruqb9dtzOhSWCaBQ9YGEhkX+BrkBSxfm5fwSgHKY0r/mFsOn+RMGI+6oGe4SANIol8cG/f//PU//mkXBcSkLd1yUTOPduWXPg0W0wl9UFxFWSe+qQvvpnN2l97j+v+ygMNkxLG/VUvKib5hAiOOsjW7mWO0fRsgLIpdmw4JYdzYVl9elppXigSueyXijD3eK8YdSzF21K8GZnU0iPgbVqo5gsUNvY/NnSVWObrxIPI9ZhzYzirVsbMbSV4FjEQ1XzsP4EdHnru2xHHsj6a9a4bH5A1L8Y7Bo55DJb7lq5s4B+JG2m7JM7kl3hkA1UYR/NOsqGWa0ZJnCWphNFXw4pwoDa3E/KpyfRxTXvRBVoCqea4PRPiT9/AQ+1kuU=
eJxNkUlv2zAQhf9KbjqkMEltsQLkINlKtZa25UVC0ANtarVJWxJtNyr63yu2qNHDAPPezHyHNz+Vg+iV1ydkGIZqmZquITj98qTc8m50FTSBE1MZNVmP8uO77GI5kJ54eJ1PJQNCC8JRssfgf7b6j93XJZeMPLjT5ijwfbCX1RUkVZoH+pB9Cy9+2oYifF/3OI423Mwa/Vx81TfNMUZw1mNXu5U7TzNpAdTSbnh0pyd74Th9dl5pAaiyuTottOF5cdlwFriLNiPGZucyyE6Rs2pxQhaobVzx7kx1a5uv0sBAvDNMGydbv7YS6GrRqUiGqhZx/QOw5b3v6I68kPXnrPH5/IhYeLX4DXvkOlvuWrVzwPREWqod0mdCb3CgA9P4vlljOsxq07KBt7Q9jD89UsQRc0WYlm9vMsN9t53LsBBEY3IvBpSp7X1pKZUQl/4VgHKYsLwWV8InhzMDY99XNTggBCRB+XPRreTJB7LUETPGLDkPpUul6rLk8vHve379BuQ8ksc=
eJxNkEmP2kAQhf/K3HyYiF68DB5pDjZ44jUNmMXWKIeG9gptsN1AxlH+e9yJgnIo6b1XqlLV91Oha+X16eP7lyelr4pm1Erm31l9FOQ+WMvyCuIyyXxtSL8FFy9pAxG8r3sShZvGSGvtnH/VNvUxQnDWE0e9FTtXNVgOcGHVTXhnJ2th2316Xqk+KNM5nubq8Ly4bBruO4s2pfpm53DIT6G9aklMF6itHfFuTzVzm60SX0dNpxsWibdeZcbQUcNTHg9lJaLqB+DLe9+xHX2h689Z7TXzI+LB1WxuxKXX2XLX4s4G0xNtmXpInim7wYENXG329ZqwYVYZpgXcpeUS8unSPAq5I4KkeHtTRhYH0Y8okK7r2DSwiZGBx5RGko/sdx6TfQhNCEe79yREpRTi0r8CUAwTnlXiSpvJ4czBqPuyAgeEgJxVJOzjA7t4KP5Q+247lxpBNK5/0eHfcCWzD2TiMURwKtOH06TDmqw/W/+7H/27/5Z18gE0gRND+fUbPhuSzQ==
eJxNkElv4kAQhf9Kbj5kRHd7AyPlYIMzXtOAWWxFc2hor9AG2w0kHs1/jzujQXMo6b1XqlLV91sia2n69P7rx5PUlXk9aCn17rQ6cnzvzWVxBVERp57aJ2/+xY0bn/uv6w6HwabWk0o9Zz/VTXUMEZx12FZu+c5RdJoBOTerOrjTk7mwrC45rxQPFMlcnmRK/7y4bGrm2YsmIdpmZzPIToG1anBEFqipbP5qTVRjm65iT0N1q+kmjrZuaUTQVoJTFvVFycPyA7DlvWvpjozJ+nNWufX8iJh/Neobdsh1ttw1cmuByYk0VDnEz4TeYE97ptT7ao1pPyt1wwTO0nQw/nRIFgbM5n6cv7xIA4sD7wYUSNM02dBlQ0ZjeUhJKPiIfutS0YfQgHCwe1dAlArOL90UgLwfsbTkV1KPDmcGBt0VJTggBMSsJGAfH9j5Q7GH2rfbudAIomH9WIN/w5XI3pEhDyGCE5E+nCqcrIr63vrf/ejf/be0FQ+gERzp0p8vPwGSzw==
二、 getPoiList接口调用
1. 概述
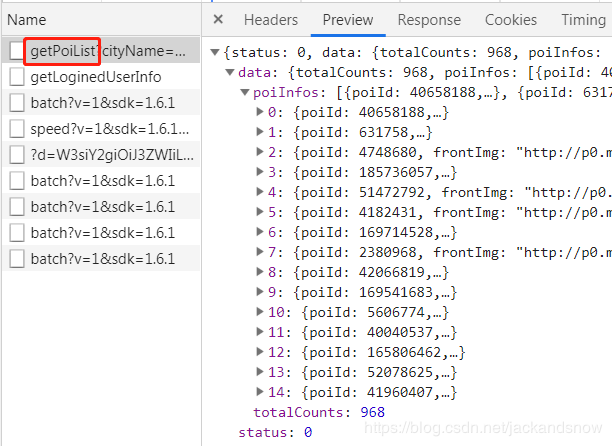
上面讲述完解析和生成美团token之后,下面主要讲述如何调用美团的getPoiList接口来获取返回json格式的店铺数据。getPoiList接口返回的数据如下图所示:
2. 模拟浏览器请求
美团的数据经常会被人爬取,所以美团公司的反爬工作做得也是非常好,因此在调用接口时一定要模拟浏览器请求,具体模拟请求的参数如下,最重要的就是使用不同的 User-Agent:1
2
3
4
5
6
7
8
9simulateBrowserHeader = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'gz.meituan.com',
'Referer': 'https://gz.meituan.com/meishi/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
3. URL编码
在发送URL请求时会进行URL编码,细心的小伙伴会从浏览器的请求header中看到,URL请求中的特殊字符(如’/‘, ‘:’, ‘+’, ‘=’)会被编码为其他的特殊字符串,比如下图中的’:’被编码为’%3A’,’/‘被编码为’%2F’等。
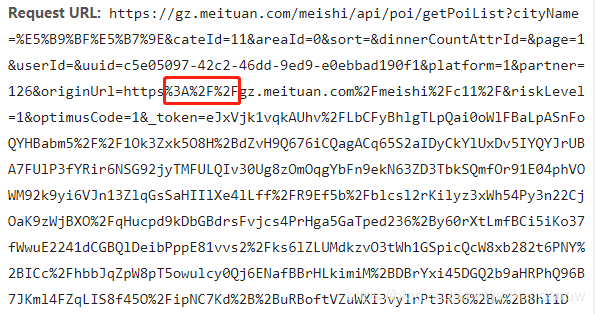
因此,这里需要编写一个简单的函数对URL请求中的特殊字符进行替换处理,具体的代码如下所示(从上图中与URL中的_token对比,可以分析出这几个特殊符号编码后的字符串):1
2
3
4
5
6# 替换'/+=:'这几个特殊符号,用于URL请求
def str_replace(string):
return string.replace('/', '%2F') \
.replace('+', '%2B') \
.replace('=', '%3D') \
.replace(':', '%3A')
4. 调用getPoiList接口
在前面所有的预备工作都准备好之后,就可以进行接口的调用了,虽然这个接口传入的参数很多,但是参数的命名都是清晰易懂的,所以就不对参数进行详细介绍了,直接上调用接口的代码吧。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34if __name__ == '__main__':
cityName = '广州'
originUrl = str_replace('https://gz.meituan.com/meishi/c11/')
# 生成token
token_encode = encode_token()
token = str_replace(token_encode)
url = 'https://gz.meituan.com/meishi/api/poi/getPoiList?' \
'cityName=%s' \
'&cateId=11' \
'&areaId=0' \
'&sort=' \
'&dinnerCountAttrId=' \
'&page=1' \
'&userId=' \
'&uuid=05bf3db6-3c2f-41cd-a4ec-ed79ae0a9506' \
'&platform=1' \
'&partner=126' \
'&originUrl=%s' \
'&riskLevel=1' \
'&optimusCode=1' \
'&_token=%s' % (cityName, originUrl, token)
response = requests.get(url, headers=simulateBrowserHeader)
if response.status_code == 200:
data = response.json()['data']
with open('data.json', 'w') as f:
json.dump(data, f, ensure_ascii=False)
print('Save data into json file successfully!')
f.close()
if response.status_code == 403:
print('Access is denied by server!')
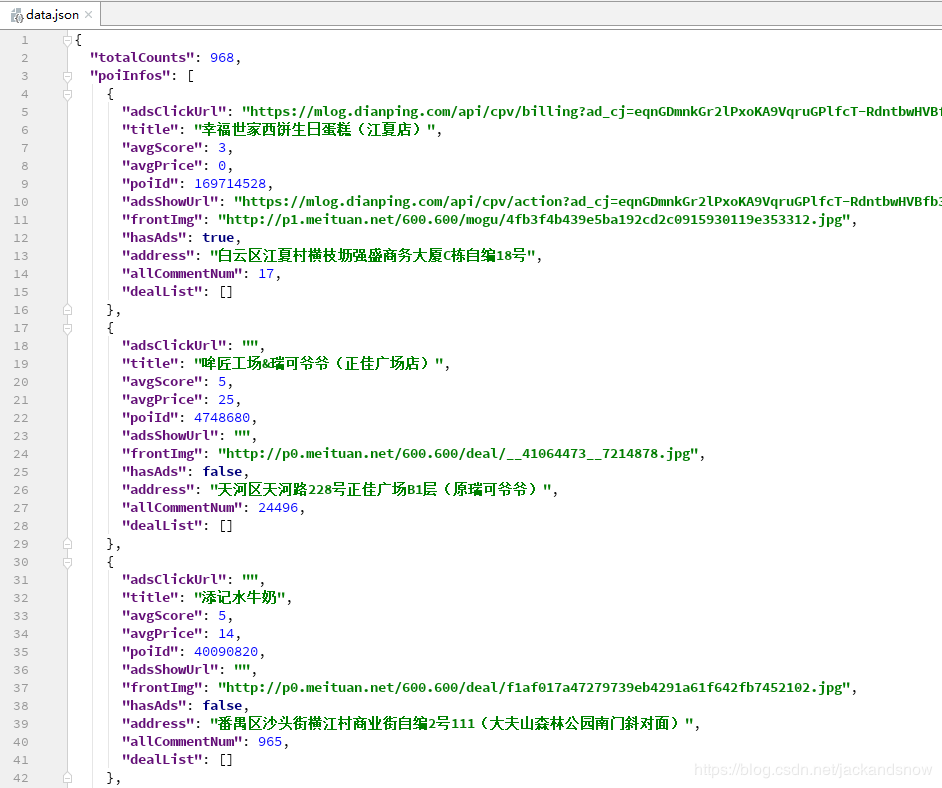
上述中URL请求中的参数除了cityName、originUrl、token可以修改外,还有cateId、page也是可以修改的,关于参数的动态调整在下一节会详细介绍。这里只是把getPoiList接口返回的json数据就简单的保存为了json格式的文件(部分内容如下图所示),后续会介绍如何获取分页的数据并把它存储到数据库中。
三、 获取分页数据并存入MySQL数据库
1. 概述
前两节已经介绍了破解美团的token以及如何进行getPoiList接口调用,下面要讲解的内容主要包括两个方面:一是获取店铺的分页数据,二是将分页数据存入MySQL数据库。
2. 获取店铺的分页数据
在第二节调用接口的基础上,这里只需要对URL中的参数进行调整,就能够获取到店铺的分页数据。具体需要调整的参数主要有 cateId、page 和 originUrl 三个,第一个是指菜系的类别,第二个是指当前所在页,第三个是指获取分页需要调的URL。下面代码就是实现如何获取菜系ID以及调整URL参数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36# get category id
def get_cateId(link_url):
splits = link_url.split('/')
return splits[-2].replace('c', '')
# call interface to get json data
def call_interface(page, originUrl):
cityName = '广州'
cate_id = get_cateId(originUrl)
originUrl = str_replace(originUrl)
token = str_replace(encode_token())
url = 'https://gz.meituan.com/meishi/api/poi/getPoiList?' \
'cityName=%s' \
'&cateId=%s' \
'&areaId=0' \
'&sort=' \
'&dinnerCountAttrId=' \
'&page=%s' \
'&userId=' \
'&uuid=05bf3db6-3c2f-41cd-a4ec-ed79ae0a9506' \
'&platform=1' \
'&partner=126' \
'&originUrl=%s' \
'&riskLevel=1' \
'&optimusCode=1' \
'&_token=%s' % (cityName, cate_id, page, originUrl, token)
response = requests.get(url, headers=simulateBrowserHeader)
if response.status_code == 200:
data = response.json()['data']
return data
if response.status_code == 403:
print('Access is denied by server!')
return {}
下一步需要先从美团首页爬取不同菜系的url列表dish_url_list,然后遍历dish_url_list列表,获取每个菜系的所有分页数据。注意调用getPoiList接口会返回该菜系的总店铺数totalCounts,因此可以计算出每个菜系的总页数,最后就能调用call_interface() 方法获取每个菜系的分页数据了。实现的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class FoodSpider(scrapy.Spider):
name = 'food'
allowed_domains = ['gz.meituan.com']
start_urls = ['https://gz.meituan.com/meishi/']
def parse(self, response):
# 所有菜系URL
dish_url_list = response.xpath('//*[@id="app"]//*[@data-reactid="20"]/li/a/@href').extract()
# print(dish_url_list)
# traverse each dish_url to get food data
for dish_url in dish_url_list:
yield Request(dish_url.replace('http', 'https'), callback=self.parse_food)
def parse_food(self, response):
origin_url = response.url
print('crawl food from ' + origin_url)
dish_type = response.xpath('//*[@id="app"]//*[@class="hasSelect"]/span[2]/text()').extract()[0]
re_data = call_interface(1, origin_url)
data_list = get_food_list(dish_type, re_data['poiInfos'])
# calculate how many pages
if re_data['totalCounts'] % 15 == 0:
page_num = re_data['totalCounts'] // 15
else:
page_num = re_data['totalCounts'] // 15 + 1
for page in range(2, page_num + 1):
re_data = call_interface(page, origin_url)
data_list.extend(get_food_list(dish_type, re_data['poiInfos']))
write_to_db(data_list)
3. 将分页数据存入MySQL数据库
首先需要创建数据库表,根据自己对店铺数据的需要选择使用的字段,如果有想要偷懒或者闲麻烦的小伙伴,可以直接复制下面的SQL语句创建表。1
2
3
4
5
6
7
8
9
10
11
12create table tb_restaurants
(
pk_id char(36) not null comment '主键',
dish_type varchar(20) not null comment '所属菜系',
restaurant_name varchar(50) not null comment '餐厅名称',
location varchar(100) not null comment '餐厅地址',
price int not null comment '人均价格',
star float not null comment '评分',
img_url varchar(200) not null comment '餐厅图片链接',
comment_num int not null comment '评论数量',
primary key (pk_id)
);
然后需要根据数据库表,创建相应的实体类,并初始化所有数据成员都是None,代码如下所示。关于 to_json() 方法,是为了便于把获取的数据保存为json文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class MeituanItem:
def __init__(self):
self.pk_id = None
self.dish_type = None
self.restaurant_name = None
self.location = None
self.price = None
self.star = None
self.img_url = None
self.comment_num = None
# transfer to dict, convenient to save as json file
def to_json(self):
return {
'pk_id': self.pk_id,
'dish_type': self.dish_type,
'restaurant_name': self.restaurant_name,
'location': self.location,
'price': self.price,
'star': self.star,
'img_url': self.img_url,
'comment_num': self.comment_num
}
接着需要返回的数据转换为实体对象列表。下面代码中的category参数是指菜系类别,poiInfos参数是dict类型,就是调用getPoiList接口返回的json数据,其具体返回的属性值详见下图所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# get food detail from poiInfos
def get_food_list(category, poiInfos):
item_list = []
for i in range(0, len(poiInfos)):
item = MeituanItem()
item.pk_id = str(uuid.uuid1())
item.dish_type = category
item.restaurant_name = poiInfos[i]['title']
item.location = poiInfos[i]['address']
item.price = 0 if poiInfos[i]['avgPrice'] is None else int(poiInfos[i]['avgPrice'])
item.star = float(poiInfos[i]['avgScore'])
item.img_url = poiInfos[i]['frontImg']
item.comment_num = int(poiInfos[i]['allCommentNum'])
item_list.append(item)
return item_list

最后使用pymysql建立数据库连接,配置好host、port、user、password、database这几个参数,写入数据库这里使用的是原生的SQL语句方式,就不多做介绍了,直接看下面的代码吧。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# write data into mysql database
def write_to_db(item_list):
# mysql connection information
conn = pymysql.Connect(
host='127.0.0.1',
port=3306,
user='root',
password='123456',
database='meituan',
charset='utf8')
cursor = conn.cursor()
# insert into database one by one
for item in item_list:
sql = 'INSERT INTO TB_RESTAURANTS(pk_id, dish_type, restaurant_name, location, price, star, img_url,' \
' comment_num) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)'
params = (item.pk_id, item.dish_type, item.restaurant_name, item.location, item.price, item.star, item.img_url,
item.comment_num)
# excute sql
cursor.execute(sql, params)
# commit
conn.commit()
cursor.close()
# close connection
conn.close()
print('Write data into MySQL database successfully!')
写入数据成功后,可以在数据库中查询到有上万条的店铺数据,如下图所示:
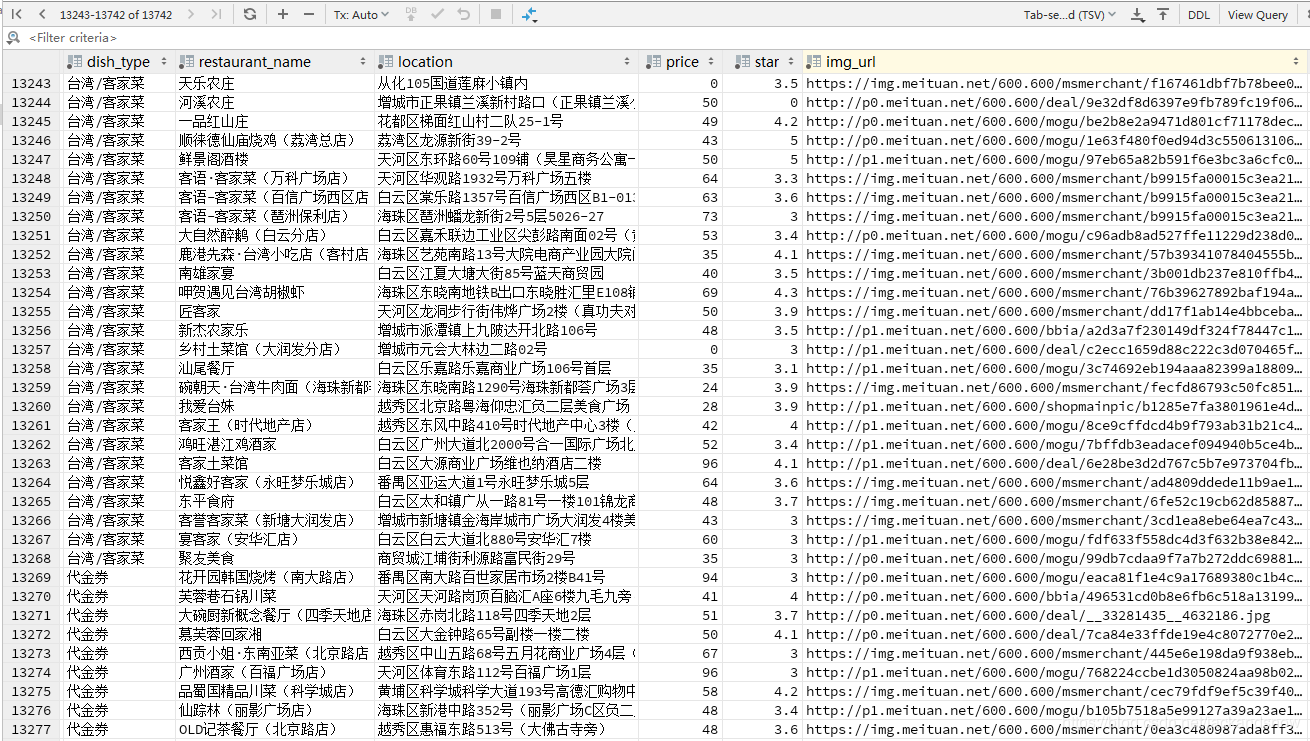
四、 致谢
至此,爬取美团店铺数据整个流程都已经讲解完了,如果有需要整个项目源码的小伙伴,可前往github链接去下载。如果你觉得笔者写得还不错,还请在项目上点个star,感谢!
...
...