一、前言
相信大多数朋友们在使用Pandas读取Excel数据(如csv文件)时,表格中往往含有异常的值。这些异常值通过包括三大类: None,null,NaN。但是None和null通常可以通过“==”来判断,相对比较简单,因此本文主要介绍对NaN异常值的处理。众所周知,NaN其实指的是 Not A Number,也就是说不是一个数。
二、判断是否含有 NaN
在Pandas DataFrame中判断是否含有NaN值的方法是pd.isna(),下面就以实际例子给大家展示下:
1.首先这是使用Pandas读出来的原始数据,从下图中可以看到其中包含很多NaN值。
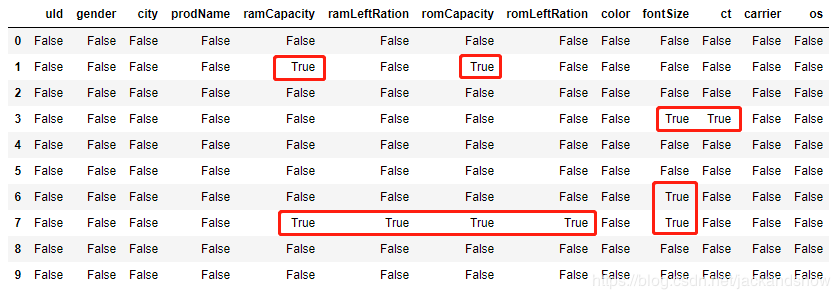
2.使用isna() 方法会返回一个仅含True和False这两种值的DataFrame,该方法主要用来判断表格中的每一个元素是否为NaN,使用方法很简单,就是your_dataframe.isna(),最后得到的结果如下图所示。可以看到,之前为NaN值的那些位置,都已经成功判断出来了。
3.使用isna().any() 方法会返回一个仅含True和False这两种值的Series,这个方法主要是用来判断所有列中是否含有NaN值,使用方法也是your_dataframe.isna().any(),返回的结果如下图所示。

三、删除表中全部为NaN的行或列
由于笔者这个表中没有全部为NaN的行或列,执行后表也不会有丝毫变化,这里就不放结果图了,下面主要介绍下使用的方法。
1.删除DataFrame表中全部为NaN的行1
your_dataframe.dropna(axis=0,how='all')
2.删除DataFrame表中全部为NaN的列1
your_dataframe.dropna(axis=1,how='all')
四、删除表中含有任何NaN的行或列
1.删除表中含有任何NaN的行1
your_dataframe.dropna(axis=0,how='any')
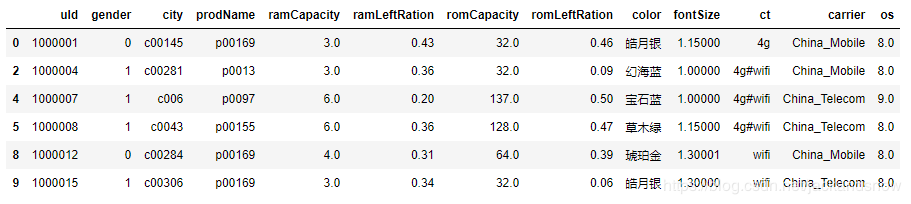
删除之后的结果如下图所示,结合第二步中的原始数据可知,表中第1、3、6、7这四行中含有NaN值,所以下图中这几行被成功删除。
2.删除表中含有任何NaN的列1
your_dataframe.dropna(axis=1,how='any')
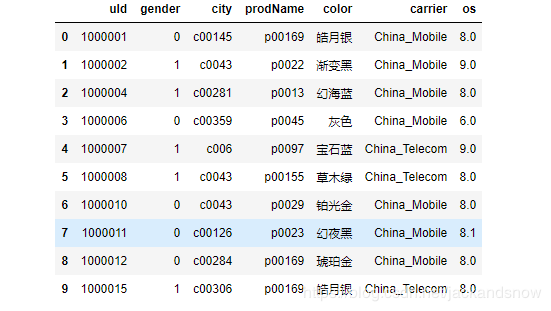
删除之后的结果如下图所示,结合第二步中的原始数据可知,表中“ramCapacity”、 “ramLeftRation”、 “romCapacity”、 “romLeftRation”、 “fontSize”、 “ct”这几列中含有NaN值,所以下图中这几列被成功删除。
五、替换所有 NaN 的值
替换所有 NaN 的值主要用的是fillna() 方法,其具体使用方法如下:1
2
3
4
5
6# 替换后的值
replace_value = 0.0
# 这里设置 inplace 为 True,能够直接把表中的 NaN 值替换掉
your_dataframe.fillna(replace_value, inplace=True)
# 如果不设置 inplace,则这样写就行
# new_dataframe = your_dataframe.fillna(replace_value)
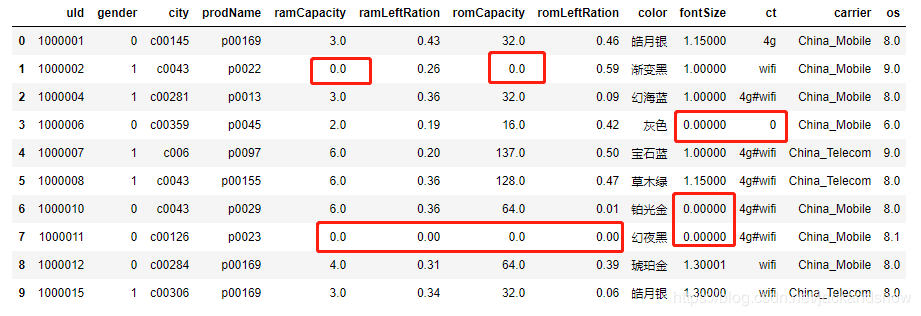
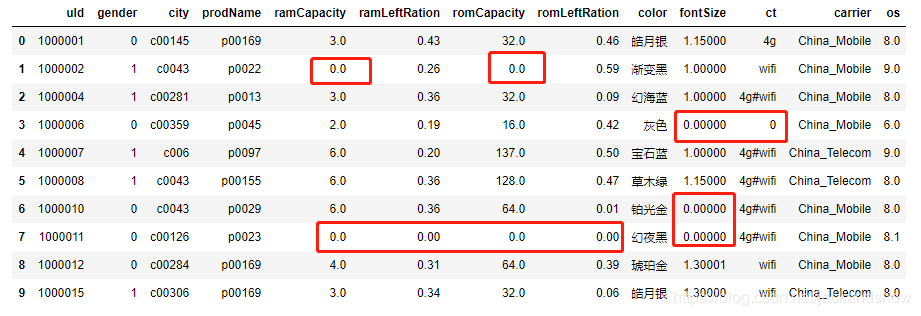
替换后的结果如下图所示,可以看到所有NaN值都已成功替换。
...
...