本篇文章是对LeetCode平台的热题Hot 100的题目讲解和基于Python的代码实现的的总结,所有代码都可前往此Github下载,仅供大家学习参考使用。
1. 两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
1.1 解题思路
这是一个简单题,题目清晰易懂。首先会想到的方法就是暴力法,做法就是使用双重循环,找到和为 target 的两数的下标。虽然该方法能够找到正确的解,但是运行效率极其低下,不到万不得已不建议使用这种方法。
接下来重点要说的方法是使用Hash表,做法就是首先将 nums 中所有元素及其下标添加到 Hash表中,然后遍历 nums 中每一个 value,再到 Hash表中寻找 target - value 是否存在,如果存在则返回下标,从而返回答案。
1.2 Python程序
(1)暴力法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12class Solution:
def twoSum(self, nums, target):
"""
暴力法,两重循环搜索解
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
for i in range(len(nums)):
for j in range(i + 1, len(nums)):
if nums[i] + nums[j] == target:
return [i, j]
(2)Hash表的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution(object):
def twoSum(self, nums, target):
"""
利用字典实现 Hash表
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
# 转换为 (value, id) 字典
dic = dict(map(lambda x: (x[1], x[0]), enumerate(nums)))
for i, v in enumerate(nums):
j = dic.get(target - v)
# 找到 target-v 且不是本身
if j and i != j:
return [i, j]
2. 两数相加
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例:
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4)
输出:7 -> 0 -> 8
原因:342 + 465 = 807
2.1 解题思路
这是一个中等难度题,其实题目很简单,就是按照倒序的方式将两个数相加,问题在于这两个数的每一位都以链表的形式存储,难点在于如何对不同长度的链表对应位相加以及进位如何处理。用数学的思维来思考,其实也简单,对于不同长度的链表,只需要把短链表缺的部分补0即可;进位处理每次只需在相加后设置一个进位标识,然后加到结果上就完事。
2.2 Python程序
1 | # Definition for singly-linked list. |
3. 无重复字符的最长子串
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
3.1 解题思路
这是一个中等难度题,题目清晰明了,是求不含重复字符的最长子串的长度,注意是求子串而不是子序列。显然,子串必定的连续的字符组合,故最简单的解法就是滑动窗口法,具体做法如下:
(1)设置一个滑动窗口,用于存储当前不含重复字符的最长子串;
(2)遍历输入字符串 s,对每个字符 s[i] 进行判断:
a. 如果 s[i] 不在滑动窗口中,则将其添加进去;
b. 如果 s[i]在滑动窗口中,此时需先记录当前获得的最大长度,然后找到 s[i] 在滑动窗口中的位置 j,截断滑动窗口中 j 及之前的部分,并将 s[i] 添加到剩余部分的末尾。
(3)遍历完字符串 s 后,再次比较当前记录的最大长度与滑动窗口的长度,返回其中最大值。
上述滑动窗口法的时间复杂度为 O(N2),遍历字符串为 O(N),查找 s[i] 的重复位置也为 O(N)。当然,该算法能够继续被优化,那就是将查找 s[i] 的重复位置优化为 O(1),那么优化后的算法复杂度将变为 O(N)。优化的做法就是使用哈希字典来存储处理每个字符时的最大子串长度,步骤与上面类似:
(1)定义一个空的哈希字典,并设置最大长度的子串起始位置 start 为 0;
(2)遍历字符串 s,对每个字符 s[i] 进行判断:
a. 如果 s[i] 不在哈希字典中,则将其添加进去,此时记录当前获得的最大长度;
b. 如果 s[i] 在哈希字典中,则更新 start 为 s[i] 所在的位置 j,之后同上个步骤将其添加到哈希字典,记录当前获得的最大长度。
3.2 Python程序
(1)滑动窗口法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution(object):
def lengthOfLongestSubstring(self, s):
"""
滑动窗口法
:type s: str
:rtype: int
"""
maxn = 0
# 保存当前最长的子串
temp = ''
for c in s:
if c not in temp:
temp += c
else:
maxn = max(maxn, len(temp))
# 找到重复的字符,截断前面部分,末尾继续加
temp = temp[temp.index(c) + 1:] + c
# 若 s 只包含一个字符,则 maxn 无法更新
return max(maxn, len(temp))
(2)优化后的滑动窗口法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Solution(object):
def lengthOfLongestSubstring(self, s):
"""
滑动窗口法 + 哈希字典
:type s: str
:rtype: int
"""
maxn = 0
# 最长子串的起始位置
start = 0
dic = {}
for i, c in enumerate(s):
index = dic.get(c)
# 当前字符在字典中,更新 start
if index:
start = max(start, index)
# 添加到字典中
dic[c] = i + 1
# 记录当前最大长度
maxn = max(maxn, i - start + 1)
return maxn
10. 正则表达式匹配
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 ‘.’ 和 ‘*’ 的正则表达式匹配。
‘.’ 匹配任意单个字符
‘*’ 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s 的,而不是部分字符串。
说明:
s 可能为空,且只包含从 a-z 的小写字母。
p 可能为空,且只包含从 a-z 的小写字母,以及字符 . 和 *。
示例 1:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:
s = "aa"
p = "a*"
输出: true
解释: 因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3:
输入:
s = "ab"
p = ".*"
输出: true
解释: ".*" 表示可匹配零个或多个('*')任意字符('.')。
示例 4:
输入:
s = "aab"
p = "c*a*b"
输出: true
解释: 因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
示例 5:
输入:
s = "mississippi"
p = "mis*is*p*."
输出: false
10.1 解题思路
这是一个困难题,实质是一个字符串匹配的问题,简单对题目理解一下,最容易想到的方法就是回溯法。回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。回溯法使用的是深度优先搜索的策略,实质是一种暴力搜索法。
(1)当匹配模式串 p 不包含星号时,只需要对匹配串 s 和 p 进行每一个字符匹配即可,即判断 p[j] == '.' or p[j] == s[i]。
(2)当匹配模式串 p 包含星号时,需要检查匹配串 s 的不同后缀,以保证它们能够匹配模式串 p 的剩余部分。
但是,回溯法的效率会很差,在后面的代码中可以看到它是递归调用,所以还有一种解法就是动态规划。因为题目拥有最优子结构 ,一个自然的想法是将中间结果保存起来。通过用 dp(i,j) 表示 s[i:] 和 p[j:] 是否能匹配,从而将原本的问题转换为用更短的字符串匹配问题。而若要求得 dp(i,j),要分3种情况进行讨论:
(1)最简单的情况是 p[j] == s[i],此时 dp(i,j) = dp(i-1,j-1)。
(2)当 p[j] == '.' 时,同样 dp(i,j) = dp(i-1,j-1)。
(3)当 p[j] == '*' 时,因为星号可表示匹配零个或多个,所以又需要考虑2种情况:
a. 当星号表示匹配零次时,即 p[j-1] != s[i],此时 dp(i,j) == dp(i,j-2)。
比如: (ab, abc*),遇到星号往前看2位,发现 s[i] 的 ab 与 p[j-2] 的 ab 匹配,所以后面的 c 就被匹配了0次。
b. 当星号表示匹配至少1次时,即 p[j-1] == s[i] or p[j-1] == '.',此时
dp(i,j) == dp(i-1,j) # 多个字符匹配的情况
or dp(i,j) == dp(i,j-1) # 单个字符匹配的情况
or dp(i,j) == dp(i,j-2) # 没有匹配的情况
10.2 Python程序
(1)回溯法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution(object):
def isMatch(self, s, p):
"""
使用回溯法求解
:type s: str
:type p: str
:rtype: bool
"""
if not p:
return not s
# bool(s) 判断s是否为空
first_match = bool(s) and p[0] in {s[0], '.'}
if len(p) >= 2 and p[1] == '*':
return (self.isMatch(s, p[2:]) or
first_match and self.isMatch(s[1:], p))
else:
# 如果没有 '*',则按位匹配即可
return first_match and self.isMatch(s[1:], p[1:])
(2)动态规划算法的实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution(object):
def isMatch(self, s, p):
"""
使用自底向上的动态规划算法求解
:type s: str
:type p: str
:rtype: bool.
"""
dp = [[False] * (len(p) + 1) for _ in range(len(s) + 1)]
dp[-1][-1] = True
for i in range(len(s), -1, -1):
for j in range(len(p) - 1, -1, -1):
first_match = i < len(s) and p[j] in {s[i], '.'}
if j + 1 < len(p) and p[j + 1] == '*':
dp[i][j] = dp[i][j + 2] or first_match and dp[i + 1][j]
else:
dp[i][j] = first_match and dp[i + 1][j + 1]
return dp[0][0]
11. 盛最多水的容器
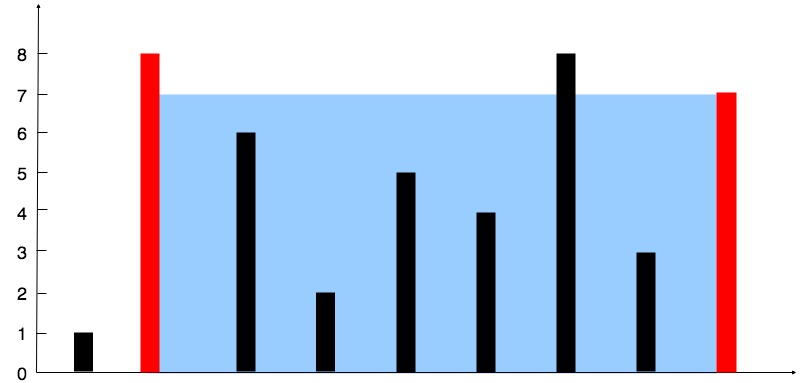
给定 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
说明:你不能倾斜容器,且 n 的值至少为 2。
1 | class Solution(object): |
1 | class Solution(object): |
1 | class Solution(object): |
示例:
输入:"23"
输出:["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"].
说明: 尽管上面的答案是按字典序排列的,但是你可以任意选择答案输出的顺序。
17.1 解题思路
这是一个中等难度题,读懂题意后可知,其实就是求每个数字所对应字母的所有排列组合,而这个排列组合可以通过树的形式表示出来,如下图所示:
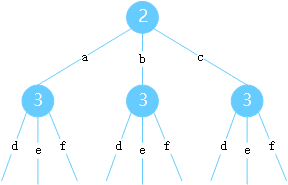
因此,原问题可以转换为求这棵树从根节点到叶子节点的所有路径,虽然常用的做法就是通过递归进行深度优先搜索,但是在这里我要另辟蹊径,为大家讲下基于广度优先搜索的做法。既然是从根节点到叶子节点,那就可以按照广度进行逐层处理,在每一层处理中更新当前找到的所有路径,直到叶子节点层处理完结束。
17.2 Python程序
1 | def help(list1, list2): |
19. 删除链表的倒数第N个节点
给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
示例:
给定一个链表: 1->2->3->4->5, 和 n = 2.
当删除了倒数第二个节点后,链表变为 1->2->3->5.
说明:给定的 n 保证是有效的。
19.1 解题思路
这是一个中等难度题,给定一个链表和N,要求删除其倒数第N个节点,并返回剩余的链表。要解决这个问题,我们需要将其转换为删除链表的顺数第 (L-N+1) 个节点,其中 L 是链表的长度。最简单的就是采用两次遍历法:第一次遍历整个链表,获得该链表的长度 L;第二次遍历删除第 (L-N+1) 个节点,即将第 (L-N) 个节点的 next 指针指向第 (L-N+2) 个节点。
然而,该题还有另外一种更高效的方法,即一次遍历法。使用双指针,命名为 first 和 second,初始两个指针的下一个节点都是首节点,然后循环N次使第一个指针指向第 N 个节点,接着循环L-N次使第二个指针指向第 L-N 个节点,从而将第 L-N+1 个节点删除。虽然此处有两重循环,但是循环的总次数刚好等于 L,故相当于是链表的一次遍历。
19.2 Python程序
(1)两次遍历法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution(object):
def removeNthFromEnd(self, head, n):
"""
两次遍历法
:type head: ListNode
:type n: int
:rtype: ListNode
"""
total = 1
curr = head
while curr.next:
total += 1
curr = curr.next
# 顺数第 m 个节点
m = total - n + 1
# 只有一个节点或者要删除的是首节点
if not head.next or m == 1:
return head.next
# 找到要删除节点的前一个节点
curr = head
while m - 1 > 1:
curr = curr.next
m -= 1
delete = curr.next
curr.next = delete.next
return head
(2)一次遍历法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution(object):
def removeNthFromEnd(self, head, n):
"""
一次遍历法
:type head: ListNode
:type n: int
:rtype: ListNode
"""
first = ListNode(0)
first.next = head
second = first
# first指向第 N 个节点
for i in range(n):
first = first.next
# second指向第 L-N 个节点
while first.next:
first = first.next
second = second.next
# 要删除的是首节点
if second.next == head:
return head.next
# 删除第 L-N+1 个节点
else:
second.next = second.next.next
return head
20. 有效的括号
给定一个只包括 ‘(‘,’)’,’{‘,’}’,’[‘,’]’ 的字符串,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
示例 1:
输入: "()"
输出: true
示例 2:
输入: "()[]{}"
输出: true
示例 3:
输入: "(]"
输出: false
示例 4:
输入: "([)]"
输出: false
示例 5:
输入: "{[]}"
输出: true
20.1 解题思路
这是一个简单题,如果有学过数据结构的同志,其实都应该做到过这个题目,因为这正是栈的一个经典应用案例。众所周知,栈的特点就是“先入后出”,而这正是此题括号匹配的关键:若遇到左括号则入栈,而若遇到右括号,则将栈顶的左括号出栈然后进行括号的匹配即可。
20.2 Python程序实现
基于list模拟栈方法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32class Solution(object):
def isValid(self, s):
"""
:type s: str
:rtype: bool
"""
# 空字符串
if not s:
return True
dic = {
'(': ')',
'[': ']',
'{': '}'
}
stack = []
for c in s:
# 栈不为空
if stack:
top = dic.get(stack[-1])
# 如果是右括号
if not top:
return False
# 匹配栈顶左括号
if c.__eq__(top):
stack.pop()
# 不匹配就压栈
else:
stack.append(c)
else:
stack.append(c)
# 栈为空表示所有括号匹配
return not stack
21. 合并两个有序链表
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
21.1 解题思路
这是一个简单题,可能很多人和我一样最开始的想法是:先将两个链表的所有元素都取出到list中,然后进行排序,最后生成有序链表。该方法固然可行,但是时间复杂度过大。其实仔细思考后,会发现题目中的“有序”两个字很关键,因为给定的两个链表自身就是排好序的,于是就能想到:把一个链表的元素按顺序插入到另一个链表中。具体做法如下:
(1)定义一个用于保存结果的新链表 result;
(2)l1 和 l2 指针不断向后移动,比较二者当前所指向元素的大小,此时可分为以下几种情况:
a. 若 l1.val <= l2.val,则 result 末尾添加 l1.val;否则添加 l2.val。
b. 若l1 指针移到末尾,则只需将 l2 追加到 result 末尾即可。
c. 若l2 指针移到末尾,则只需将 l1 追加到 result 末尾即可。
21.2 Python程序实现
1 | # Definition for singly-linked list. |
22. 括号生成
给出 n 代表生成括号的对数,请你写出一个函数,使其能够生成所有可能的并且有效的括号组合。
例如,给出 n = 3,生成结果为:
[
"((()))",
"(()())",
"(())()",
"()(())",
"()()()"
]
22.1 解题思路
这是一个中等难度题,看了题目后最容易想到简单粗暴的暴力法,即先求得 n 对括号能够组合的 22n 个括号序列,然后检查每一个序列是否有效。显然,这样的做法是不可取的,下面给大家讲解采用动态规划并且简单易懂的方法。
首先,有效的括号序列必须是从左往右每个左括号都能匹配到右括号的,那么向有效的括号序列中插入一对括号 ‘()’ 后的序列也必然是有效的。由此,上述的问题就可以转换为:向 N-1 对括号的有效序列中插入一对括号(总共就是 N 对括号),求插入后所有的括号序列。再者,由于插入的一对括号 ‘()’ 本身也是有效序列,故插入的位置可以在原有效序列中任意一个位置。具体做法如下:
(1)循环遍历 i= to N,求出每个 i 的所有有效的括号序列:
a. 若 i=1,则返回一组有效括号序列。
b. 若 i>1,遍历 i-1 对括号的所有括号序列,然后需要遍历每一个括号序列,在每个单括号后插入一对括号,从而得到 i 对括号的所有括号序列。其中,需要注意的是,每次插入一对括号后的括号序列存在重复,因此需要使用集合 set 对结果进行去重。
c. 将求得的 i 对括号的括号序列集合转换为 list,保存到结果列表 result 中。
(2)返回结果列表 result 中的最后一个元素,即 N 对括号生成的所有有效括号序列。
22.2 Python程序
动态规划方法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31def new_insert(st):
"""
在有效括号序列中插入一对新的括号
:param st: 有效括号序列
:return: 插入后的有效括号序列
"""
if not st:
return {'()'}
result = set()
for s in st:
for i in range(len(s)):
result.add(s[:i+1] + '()' + s[i+1:])
return result
class Solution(object):
def generateParenthesis(self, n):
"""
动态规划方法
:type n: int
:rtype: List[str]
"""
# 保存 i=1 to n 对括号的生成结果
result = []
temp = set()
while n > 0:
temp = new_insert(temp)
result.append(list(temp))
n -= 1
return result[-1]
23. 合并K个排序链表
合并 k 个排序链表,返回合并后的排序链表。请分析和描述算法的复杂度。
示例:
输入:
[
1->4->5,
1->3->4,
2->6
]
输出: 1->1->2->3->4->4->5->6
23.1 解题思路
这是一个困难题,在前面做过21题(合并两个有序链表)后,难免会有这样的想法:将 K 个有序链表从前往后进行两两合并,即将前面两个链表合并后的结果拿去与后面的链表进行两两合并,直到合并完 K 个链表。然而,这样的想法不可行,因为在合并两个链表的过程中,至少要对每个链表遍历一次,因此合并过程越到后面(合并后的链表会越来越长)所花费的时间会越多。
这里讲解另一种思路,同样的基于有序插入的思想,具体做法如下:
(1)遍历 K 个链表,将每个链表中的元素有序插入到空列表 result 中;
(2)遍历 result 列表,将每个元素转换为 ListNode 节点插入到空链表,并返回结果。
23.2 Python程序
1 | # Definition for singly-linked list. |
31. 下一个排列
实现获取下一个排列的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
必须原地修改,只允许使用额外常数空间。
以下是一些例子,输入位于左侧列,其相应输出位于右侧列。
1,2,3 → 1,3,2
3,2,1 → 1,2,3
1,1,5 → 1,5,1
31.1 解题思路
这是一个中等难度题,该题最关键的地方在于字典序。字典序排序算法是一种对于随机序列生成全排列的排序方法,其求解步骤如下:
(1) 从右至左找出数组(序列)中第一个正序(左边数字小于右边数字),计左边数字的下标为 left,计当前左边数字为 leftValue;
(2) 再次从右边至左边找出第一个比 leftValue 大的数,此时该数的下标记为 right,交换两者;
(3) 将从 left+1 到数组的末尾的数按从小到大排序,得到最小排列;
(4) 重复步骤(1)(2)(3),直到找出所有的排列组合。
看懂了上面的字典序排序算法后,其实该题就迎刃而解了,只需要执行上述算法中的(1)(2)(3)步骤,便能求得当前数字序列的下一个更大的排序。,
31.2 Python程序
字典序排序算法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution(object):
def nextPermutation(self, nums):
"""
:type nums: List[int]
:rtype: None Do not return anything, modify nums in-place instead.
"""
i = len(nums) - 2
# 找到 num[i+1] > nums[i] 的位置
while i >= 0 and nums[i + 1] <= nums[i]:
i -= 1
if i >= 0:
j = len(nums) - 1
# 寻找比 nums[i] 略大的数 nums[j],并交换位置
while j >= 0 and nums[j] <= nums[i]:
j -= 1
nums[i], nums[j] = nums[j], nums[i]
# 反转 nums[i] 后面的所有数字,以获取它们的最小排列
l, r = i + 1, len(nums) - 1
while l < r:
nums[l], nums[r] = nums[r], nums[l]
l += 1
r -= 1
48. 旋转图像
给定一个 n × n 的二维矩阵表示一个图像。
将图像顺时针旋转 90 度。
说明:
你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。
示例 1:
给定 matrix =
[
[1,2,3],
[4,5,6],
[7,8,9]
],
原地旋转输入矩阵,使其变为:
[
[7,4,1],
[8,5,2],
[9,6,3]
]
示例 2:
给定 matrix =
[
[ 5, 1, 9,11],
[ 2, 4, 8,10],
[13, 3, 6, 7],
[15,14,12,16]
],
原地旋转输入矩阵,使其变为:
[
[15,13, 2, 5],
[14, 3, 4, 1],
[12, 6, 8, 9],
[16, 7,10,11]
]
48.1 解题思路
这是一个中等难度题,题目要求了不能使用另一个矩阵来旋转原始图像,故只能在原始矩阵上进行替换操作,具体做法其实也很简单:
(1)边界条件判断:我们只关心矩阵维数 N > 1 的情况;
(2)设置一个 N×N 的布尔数组,标识每个元素是否被处理过;
(3)双重循环遍历矩阵中的每一个元素,首先判断该元素是否被处理过,若未处理过则进行元素替换,替换的规则如下:
a. 对于任一元素 M[i][j],它将被旋转到 M[j][N-1-i],故需将 M[j][N-1-i] 替换为 M[i][j],即 M[j][N-1-i] = M[i][j];
b. 对于 M[j][N-1-i],它将被旋转到 M[N-1-i][N-1-j],故需将 M[N-1-i][N-1-j] 替换为 M[j][N-1-i],即 M[N-1-i][N-1-j] = M[j][N-1-i];
c. 对于 M[N-1-i][N-1-j],它将被旋转到 M[N-1-j][i],故需将 M[j][N-1-i] 替换为 M[N-1-i][N-1-j],即 M[N-1-j][i] = M[N-1-i][N-1-j];
d. 对于 M[N-1-j][i],它将被旋转到 M[i][j],故需将 M[i][j] 替换为 M[N-1-j][i],即 M[i][j] = M[N-1-j][i]。
48.2 Python程序
1 | class Solution(object): |
49. 字母异位词分组
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
输入: ["eat", "tea", "tan", "ate", "nat", "bat"],
输出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
49.1 解题思路
这是一个中等难度题,解题的思路很简单,既然是找所有字母都相同的字符串,那么把所有字符串按照字母序排序,然后比较是否相等就能分辨出字母异位词了。具体做法如下:
(1)定义一个空字典,用于存储分组结果;
(2)遍历输入的字符串数组,将每一个字符串排序后得到字母序字符串:
a. 若字母序不在字典中,则将字母序作为 key、实际值以list形式作为 value 新增到字典中;
b. 若字母序在字典中,则将实际值追加到与字母序作为 key 对应的 value 列表中。
(2)将每个字母序的实际值列表取出返回结果。
49.2 Python程序
1 | class Solution(object): |
53. 最大子序和
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4],
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
进阶:
如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的分治法求解。
53.1 解题思路
这是一个简单题,最常用的就是暴力法,即使用两个变量,一个用于记录当前和,另一个用于记录最大和,然后遍历输入列表,更新这两个变量得到最大和。然而,这其中含有动态规划的思想,所以此处重点说下动态规划方法的做法:
(1)定义两个变量用于保存当前和、最大和,初始化为 nums[0];
(2)遍历输入的数据列表:
a. 如果当前和大于0,说明它对最大和有增益价值,则当前和与当前数字继续加和;
b. 如果当前和小于等于0,说明它对最大和没有增益价值,则将当前和替换为当前数字;
c. 每次遍历之后,更新当前获得的最大和;
(3)遍历结束后返回最大和。
注意,题目还有进阶要求,动态规划方法的时间复杂度刚好为 O(N),下面则说说采用分治法的解题思路。如果将数组拆分为左子数组和右子数组,深入理解题目后可以得知,最大子序和出现的位置可以分为三种情况:①最大子序和在左子数组;②最大子序和在右子数组;③最大子序和跨越中间点。这样理解题目后,分治法的思想就体现很清楚了,子问题则是求左最大子序和、右最大子序和、中间最大子序和,合并子问题的解(即求三者最大值)就得到题目要求的最大子序和了。显然,求左最大子序和和右最大子序和通过递归求解即可,而求中间的最大子序和需要将中间部分拆分为左右两部分,然后将这左右两部分的最大子序和相加就得到中间的最大子序和。
53.2 Python程序
(1)动态规划方法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution(object):
def maxSubArray(self, nums):
"""
动态规划方法
:type nums: List[int]
:rtype: int
"""
# 保存当前和,最大和
curr_sum, result = nums[0], nums[0]
for num in nums:
# 对结果有增益价值,则继续加和
if curr_sum > 0:
curr_sum += num
# 无增益价值,则更换为当前数字
else:
curr_sum = num
# 更新当前获得的最大和
result = max(result, curr_sum)
return result
(2)分治法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30class Solution(object):
def maxSubArray(self, nums):
"""
分治法
:type nums: List[int]
:rtype: int
"""
n = len(nums)
if n == 1:
return nums[0]
# 左半边的最大子序和
maxleft = self.maxSubArray(nums[:n // 2])
# 右半边的最大子序和
maxright = self.maxSubArray(nums[n // 2:])
# 中间的最大子序和
m = n // 2
templ, tempr = 0, 0
mid_maxl, mid_maxr = nums[m - 1], nums[m]
for i in range(m):
templ += nums[m - 1 - i]
mid_maxl = max(mid_maxl, templ)
tempr += nums[m + i]
mid_maxr = max(mid_maxr, tempr)
# n 为奇数的时候,上面的循环会漏掉最后一个元素
if n % 2 != 0:
tempr += nums[n - 1]
mid_maxr = max(mid_maxr, tempr)
maxmid = mid_maxl + mid_maxr
# 返回全局的最大子序和
return max(maxleft, maxmid, maxright)
55. 跳跃游戏
给定一个非负整数数组,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个位置。
示例 1:
输入: [2,3,1,1,4]
输出: true
解释: 我们可以先跳 1 步,从位置 0 到达 位置 1, 然后再从位置 1 跳 3 步到达最后一个位置。
示例 2:
输入: [3,2,1,0,4]
输出: false
解释: 无论怎样,你总会到达索引为 3 的位置。但该位置的最大跳跃长度是 0 , 所以你永远不可能到达最后一个位置。
55.1 解题思路
这是一个中等难度题,题目很清楚就是判断能够跳跃到最后一个位置。这里为大家提供两种解法。
(1)第一种是动态规划算法,假设如果从某个位置能够跳跃到最后一个位置,那么称该位置为“好位置”,具体的步骤如下:
a. 首先使用一维布尔数组来标识所有位置是否为“好位置”,0表示不是,1表示是;
b. 按照从右往左的顺序遍历输入数组,依次找出所有能跳到终点的“好位置”,找到每一个“好位置”后需再次遍历寻找跳到这些“好位置”的前驱“好位置”,并更改所有“好位置”的标识为1;
c. 返回第0个位置是否为“好位置”,即第0个位置能够跳跃到终点。
由于寻找“好位置”的过程是两重循环,故该算法的时间复杂度为O(N2)。
(2)第二种是贪心算法,在理解第一种解法之后,其实我们只需要找到最左边的“好位置”,然后判断该位置是否是第0个位置即可。具体的步骤如下:
a. 首先定义一个变量表示“好位置”,并初始化为最后一个位置;
b. 从右往左遍历输入数组,检查每个位置是否能通过一次跳跃到达“好位置”,如果能则更新“好位置”为当前位置;
c. 返回“好位置”是否为第0个位置。
显然,使用贪心算法只用了一重循环,从而其时间复杂度为O(N)。
55.2 Python程序
(1)动态规划算法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Solution(object):
def canJump(self, nums):
"""
动态规划算法
:type nums: List[int]
:rtype: bool
"""
n = len(nums)
# 标记是否是跳到终点的好位置,0-不是,1-是
flag = [0] * n
flag[n - 1] = 1
# 从右往左寻找能跳到终点的所有点
for i in range(n - 2, -1, -1):
further_jump = min(i + nums[i], n - 1)
for j in range(i + 1, further_jump + 1):
if flag[j] == 1:
flag[i] = 1
break
# 最终看起点是否也能跳到
return flag[0] == 1
(2)贪心算法的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13class Solution(object):
def canJump(self, nums):
"""
贪心算法
:type nums: List[int]
:rtype: bool
"""
good_pos = len(nums) - 1
# 从右向左迭代,对每个位置检查是否存在一步跳跃可以到达最后一个位置
for i in range(len(nums) - 1, -1, -1):
if i + nums[i] >= good_pos:
good_pos = i
return good_pos == 0
...
...