1. OOP介绍
面向对象编程(Object-Oriented Programming, OOP)是划时代的编程思想变革,推动了高级语言的快速发展和工业化进程。OOP的抽象、封装、继承、多态的理念使软件大规模化成为可能,有效地降低了软件开发成本、维护成本和复用成本。因此,OOP实现了软件工程的三个目标:可维护性、可重用性和可扩展性。
传统意义上,面向对象有三大特性:封装、继承、多态,但“抽象”的理念也及其重要,因此可以统称为面向对象的“四大特性”。抽象是程序员的核心素质之一,体现程序员对业务的建模能力,以及对架构的宏观掌控力。面向对象的思维,以对象模型为核心,丰富模型的内涵,扩展模型的外延,通过模型的行为组合去共同解决某一类问题,抽象能力显得尤为重要;封装是一种对象功能内聚的表现形式,使模块之间的耦合度变低,更具维护性;继承使子类能够继承父类,获得父类的部分属性和行为,使模块更有复用性;多态使模块在复用性基础上更加有扩展性,使系统运行更有想象空间。
1.1 抽象
抽象是面向对象思想最基础的能力之一,正确而严谨的业务抽象和建模分析能力是后续的封装、继承和多态的基础,是软件大厦的无形基石。在面向对象的思维中,抽象分为归纳和演绎。归纳是从具体到本质,从个性到共性,将一类对象的共同特征进行归一化的逻辑思维过程;演绎则是从本质到具体,从共性到个性,逐步形象化的过程。在归纳过程中,需要抽象出对象的属性和行为的共性,难度大于演绎。
Java之父Gosling设计的Object类,是任何类的默认父类,是对万事万物的抽象,是在哲学方向上进行的延伸思考,高度概括了事物的自然行为和社会行为。在Object类中,就对哲学上的三大问题进行了隐约的解答:
(1)我是谁?getClass()说明本质上是谁,toString()是当前我的,名片。
(2)我从哪里来?Object的构造方法是生产对象的基本方式,clone()是繁殖对象的另一种方式。
(3)我到哪里去?finalize()是在对象销毁时触发的方法。
这里重点说下clone()方法,它分为浅拷贝、一般深拷贝和彻底深拷贝。浅拷贝只复制当前对象的所有基本数据类型,以及相应的引用变量,但没有复制引用变量指向的实际对象;彻底深拷贝是在成功clone一个对象之后,此对象与母对象在任何引用路径上都不存在共享的实例对象,但是引用路径递归越深,则越接近JVM底层对象,会发现彻底深拷贝实现难度越大,因为JVM底层对象可能是完全共享的。介于浅拷贝和彻底深拷贝之间的都是一般深拷贝。总之,慎用Object类的clone()方法,因为其默认是浅拷贝,若想实现深拷贝,则需要重写clone()方法实现引用对象的深度遍历式拷贝。
另外,Object类中还映射了社会科学领域的一些问题:
(1)世界是否因你而不同?hashCode()和equals()就是判断与其他元素是否相同的一组方法。
(2)与他人如何协调?wait()和notify()是对象间通信与协作的一组方法。
随着时代的发展,最初抽象的模型已经有部分不适用当下的技术潮流,比如finalize()方法在JDK9之后直接被标记为过时方法,而wait()和notify()同步方式事实上已经被同步信号、锁、阻塞集合等取代。
1.2 封装
封装是在抽象基础上决定信息是否公开,以及公开等级,核心问题是以什么样的方式暴露哪些信息。抽象是要找到属性和行为的共性,属性是行为的基本生产资料,具有一定的敏感性,不能直接对外暴露;封装的主要任务是对属性、数据、部分内容敏感行为实现隐藏。对属性的访问与修改必须通过定义的公共接口来进行,某些敏感方法或者外部不需要感知的复杂逻辑处理,一般也会进行封装。封装使面向对象的世界变得单纯,对象之间的关系变得简单,各人自扫门前雪,耦合度变弱,有利于维护。
设计模式七大原则之一的迪米特法则就是对于封装的具体要求,即A模块使用B模块的某个接口行为,对B模块中除此行为之外的其他信息知道得尽可能少。比如:耳塞的插孔就是提供声音输出的行为接口,只需关系这个插孔是否有相应的耳塞标记,是否是圆形的,有没有声音即可,至于内部CPU如何运算音频信息,以及各个电容如何协同工作,根本不需要去关注,这使得模块直接的协作只需忠于接口、忠于功能实现即可。
封装这件事情是由俭入奢易,由奢入俭难。属性值的访问与修改需要使用相应的getter和setter方法,而不是直接对public的属性进行读取和修改,可能有些程序员存在疑问,既然通过这两个方法来读取和修改,那与直接对属性进行操作有何区别?如何某一天,类的提供方想在修改属性的setter方法上进行鉴权控制、日志记录,这是在直接访问属性时无法做到的。若是将已经公开的属性和行为直接暴力修改为private,则依赖模块都会编译出错。所以,在不知道需要什么样的访问控制权限合适时,优先推荐使用private控制级别。
1.3 继承
继承是面向对象编程技术的基石,允许创建具有逻辑等级结构的类体系,形成一个继承树,让软件在业务多变的客观条件下,某些基础模块可以被直接复用、间接复用或增强复用,父类的能力通过这种方式赋予子类。继承把枯燥的代码世界变得更有层次感,甘油扩展性,为多态打下语法基础。
通常人们称继承是is-a关系,而判断is-a关系的标准就是里氏代换原则(Liskov Substitution Principle,LSP)。LSP是指任何父类能够出现的地方,子类都能够出现。比如:在枪战片中,警察经常提到“放下武器”,而匪徒们有的使用手枪,有的使用匕首,这些都是武器的子类。父类出现的地方,即“放下武器”,那么“放下手枪”是对的,“放下匕首”也是对的。在实际代码环境中,如果父类引用直接使用子类引用来代替,可以编译正确并执行,输出结果符合子类场景的预期,那么说明两个类之间符合LSP原则,可以使用继承关系。
继承的使用成本很低,一个关键字就可以使用别人的方法,似乎更加轻量简单。想复用别人的代码,跳至脑海的第一反应是继承它,所以继承像抗生素一样容易被滥用,而实际上我们应该谨慎使用继承,认真继承滥用的危害性,即方法污染和方法爆炸。方法污染是指父类具备的行为,通过继承传递给子类,但子类并不具备执行此行为的能力。比如:鸟会飞,鸵鸟继承鸟,但飞不了,这就是方法污染。子类继承了父类,则说明子类对象就可以调用父类对象的一切行为,而上面的例子却恰好相反。方法爆炸是指继承树不断扩大,底层类拥有的方法虽然都能够正常执行,但由于方法众多,其中部分方法并非与当前类的功能定位相关,很容易在实际编程中产生选择困难症。比如:某些综合功能的类,经过多次继承后达到上百个方法,造成了方法爆炸,因而带来使用不便和安全隐患。综上所述,提倡组合优先原则来扩展类的能力,即优先采用组合或聚合的类关系来复用其他类的能力,而不是优先使用继承。
1.4 多态
多态是以前面三个面向对象特性为基础,根据运行时的实际对象类型,同一个方法产生不同的运行结果,使同一个行为具有不同的表现形式,多态提升了对象的扩展能力和运行时的丰富想象力。这里要明确两个经常混淆的概念:override和overload,“override”译为“覆写(或重写)”,是子类实现接口,或者继承父类时,保持方法签名完全相同,实现不同的方法体,是垂直方向上行为的不同实现;而“overload”译为“重载”,方法名称是相同的,但是参数类型或者参数个数是不同的,是水平方向上行为的不同实现。多态是指在编译层面无法确定最终调用的方法体,以覆写为基础来实现面向对象特性,在运行期由JVM进行动态绑定,调用合适的覆写方法体来执行。重载是编译期确定方法调用,属于静态绑定,本质上重载的结果是完全不同的方法。
2. Java介绍
Java是一门面向对象编程语言,1995年由Sun公司首次发布。次年Java开发工具包发布,即Java Development Kit,简称JDK1.0,这是Java发展的一个重要里程碑,标志着Java成为一门独立的成熟语言。随后,Sun公司再接再厉发布了即时编译器,简称JIT(Just-in-time),不断进步的JIT技术使Java的执行速度接近甚至超越其他高级语言。JDK随着时代不断往前发展,在众多版本中,最具划时代影响力的版本是JDK5,项目代号Tiger。随着后续版本的陆续推出,Java的发展与时俱进,推出了diamond语法、函数式、模块化、var类型推断等新特性。目前最新的JDK版本是JDK11。
JRE(Java Runtime Environment)即Java运行环境,包括JVM、核心类库、核心配置工具等。其中JVM(Java Virtual Machine)即Java虚拟机,它是整个Java体系的底层支撑平台,把源文件编译成平台无关的字节码文件,屏蔽了Java源代码与具体平台相关的信息,所以Java源代码不需要额外修改即可跨平台运行。JVM不仅支撑着Java语言,还包括Kotlin、Scala、Python等其他流行语言。其中Kotlin是Jetbrains开发的跨平台语言,其语法简洁、类型安全,可以编译成字节码运行在JVM上,与Java语言非常方便地进行混合编程。
Java语言拥有跨平台、分布式、多线程、健壮性等特点,是当下比较主流的高级编程语言。它的类库非常丰富、功能强大、简单易用,对开发者友好,不仅吸收了C++的优点,还摒弃了其难以掌控的多继承、指针等概念。Java比较好地实现了面向对象理论,允许开发工程师以优雅的思维方式处理复杂的编程场景。下表总结了从JDK5到JDK11的重要类、特性和重大改变:
| 版本 | 新特性说明 |
|---|---|
| JDK5 | foreach迭代方式、可变参数、枚举、自动拆装箱、泛型、注解等重要特性。 |
| JDK6 | Desktop类和SystemTray类、使用Compiler API、轻量级HTTPServer API、对脚本语言的支持、Common Annotations等重要特性。 |
| JDK7 | Switch支持字符串作为匹配条件、泛型类型自动推断、try-with-resources资源关闭技巧、Objects工具类、ForkJoinPool等重要类与特性。 |
| JDK8 | 接口的默认方法实现与静态方法、Lambda表达式、函数式接口、方法与构造函数引用、新的日期与时间API、流式处理等重要特性。 |
| JDK9 | Jigsaw模块化项目、简化进程API、轻量级JSON API、钱和货币的API、进程改善和锁机制优化、代码分段缓存等重要特性。 |
| JDK10 | 局部变量的类型推断、改进GC和内存管理、线程本地握手、备用内存设备上的堆分配等重要特性。 |
| JDK11 | JDK11在删除了Java EE和CORBA模块,增加基于嵌套的访问控制,支持动态类文件常量,改进Aarch64内联函数,提供实验性质的可扩展的低延迟垃圾收集器ZGC等重要特性。 |
3. 类
3.1 类的定义
类的定义由访问级别、类型、类名、是否抽象、是否静态、泛型标识、继承或实现关键字、父类或接口名称等组成。类的访问级别有public和无访问控制符,类型分为class、interface和enum。
Java类主要由两部分组成:成员和方法。在定义Java类时,首先推荐定义变量,然后再定义方法。由于公有方法是类的调用者和维护者最关心的方法,因此最好首屏展示;保护方法虽然只被子类关心,但也可能是模板设计模式下的核心方法,因此重要性仅次于公有方法;而私有方法对外部来说就是一个黑盒实现,因此一般不需要被特别关注;最后是getter和setter方法,虽然它们是公有方法,但是因为承载的信息价值较低,一般不包含业务逻辑,所以所有getter和setter方法建议放到类最后。
3.2 接口与抽象类
定义类的过程就是抽象和封装的过程,而接口和抽象类则是对实体类进行更高层次的抽象,仅定义公共行为和特征。接口和抽象类的共同点是都不能被实例化,但可以定义引用变量指向实例对象。下表展示了两者在语法方面的不同点:
| 语法维度 | 抽象类 | 接口 |
|---|---|---|
| 定义关键字 | abstract | interface |
| 子类继承或实现关键字 | extends | implements |
| 方法实现 | 可以有 | 不能有,但JDK8之后允许有default实现 |
| 方法访问控制符 | 无限制 | 有限制,默认是public abstract类型 |
| 属性访问控制符 | 无限制 | 有限制,默认是public static final类型 |
| 静态方法 | 可以有 | 不能有,但JDK8之后允许有 |
| static{} 静态代码块 | 可以有 | 不能有 |
| 本类型直接扩展 | 单继承 | 多继承 |
| 本类型直接扩展关键字 | extends | extends |
抽象类在继承时体现的是is-a关系,接口在实现时体现的是can-do关系。与接口相比,抽象类通常是对同类事物相对具体的抽象,通常包含抽象方法、实体方法、属性变量。如果一个抽象类只有一个抽象方法,那么它就等同于一个接口。is-a关系需要符合里氏代换原则,例如Eagle is a Bird. Bird is a Object。can-do关系要符合接口隔离原则,实现接口的类要有能力去实现并执行接口中定义的行为,例如Plane can fly. Bird can fly.中就应该把fly定义为一个接口,而不是把fly()放在某个抽象类中,然后用Plane和Bird去继承此抽象类。因为Plane和Bird之间除了fly这个共同行为外,没有其他共同的特征。
接口是顶级的“类”,虽然关键字是interface,但是编译之后的字节码扩展名还是.class。抽象类是二当家,接口位于顶层,而抽象类对各个接口进行了组合,然后实现部分接口行为,其中AbstractCollection是最典型的抽象类,其定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14public abstract class AbstractCollection<E> implements Collection<E> {
// Collection定义的抽象方法,但本类没有实现
// Collection接口定义的方法,size()这个方法对于链表和顺序表有不同的实现方式
public abstract int size();
// 实现Collection接口的这个方法,因为对AbstractCollection的子类,它们判空的方式是一致的
// 这就是模板式设计,对于所有它的子类,实现共同的方法体,通过多态调用到子类的具体size()实现
public boolean isEmpty() {
// 实现Collection的方法
return size() == 0;
}
// 其他属性和部分方法实现……
}
Java语言中类的继承采用单继承形式,避免继承泛滥、菱形继承、循环继承,甚至“四不像”实现类的出现。在JVM中,一个类如果有多个直接父类,那么方法的绑定机制会变得非常复杂。接口继承接口,关键字是extends,而不是implements,允许多重继承,是因为接口有契约式的行为规范,没有任何具体实现和属性,某个实体类在实现多重继承后的接口时,只是说明“can do many things”。当纠结定义接口还是抽象类时,优先推荐定义接口,遵循接口隔离原则,按某个维度划分成多个接口 ,然后再用抽象类去implements某些接口,这样做可方便后续的扩展和重构。
3.3 内部类
在一个.java源文件中,只能定义一个类名与文件名完全一致的公开类,使用public class关键字来修饰。但在面向对象语言中,任何一个类都可以在内部定义另外一个类,前者为外部类,后者为内部类。内部类本身就是类的一个属性,与其他属性定义方式一致。比如,属性字段private static String str,由访问控制符、是否静态、类型和变量名组成,而内部类public class Inner{}也是按照这样的顺序来定义的,类型可以为class、enum,甚至是interface,当然在内部类中定义接口是不推荐的。内部类可以是静态和非静态的,它可以出现在属性定义、方法体和表达式中,甚至可以匿名出现,具体分为下列四种:
| 类型 | 说明 |
|---|---|
| 静态内部类 | 声明:static class StaticInnerClass{}。 |
| 成员内部类 | 声明:private class InstanceInnerClass{}。 |
| 局部内部类 | 定义在方法或者表达式的内部。 |
| 匿名内部类 | 使用:(new Thread(){}).start()。 |
1 | // 定义外部类,编译后生成OuterClass.class |
外部类与内部类之间使用$符号进行分隔,其中匿名内部类使用数字进行编号,而方法内部类使用编号加方法名称来标识是哪个方法。匿名内部类经常用来启动线程,可以借阅若干行代码;静态内部类是最常用的内部表现形式,外部可以使用OuterClass.StaticInnerClass直接访问。内部类加载与外部类通常不在同一个阶段进行,在JDK源码中,定义包内可见静态内部类的方式很常见,这样做的好处在于以下几点:
(1)作用域不会扩散到包外。
(2)可以通过“外部类.内部类”的方式直接访问。
(3)内部类可以访问外部类中的所有静态属性和方法。1
2
3
4
5
6static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
如上所示的代码就是在ConcurrentHashMap中定义的Node静态内部类,用于表示一个节点数据,属于包内可见,包内其他集合要用到这个Node时,直接使用ConcurrentHashMap.Node。仅包内可见,可以阻止外部程序随意使用此类来生成对象,Node的父类Entry是Map的静态内部类,之所以可以被Node成功继承,是因为两个外部类同属一个包。
3.4 访问权限控制
面向对象的核心思想之一就是封装,只把有限的方法和成员公开给别人,这也是迪米特法则的内在要求,使外部调用方法对方法体内的实现细节知道得尽可能少。为了实现封装,需要使用某些关键字来限制类外部对类内属性和方法的随意访问,这些关键字就是访问权限控制符。Java中的访问权限包括四个等级,权限控制严格程度由低到高,如下表所示。
| 访问权限控制符 | 任何地方 | 包外子类 | 包内 | 类内 |
|---|---|---|---|---|
| public | OK | OK | OK | OK |
| protected | NO |
OK | OK | OK |
| 无 | NO |
NO |
OK | OK |
| private | NO |
NO |
NO |
OK |
• public:
可以修饰外部类、属性和方法,表示公开的、无限制的,是访问限制最松的一级,被其修饰的类、属性和方法不仅可以被包内访问,还可以跨类、跨包访问,甚至允许跨工程访问。
• protected:
只能修饰属性和方法,表示受保护的、有限制的,被其修饰的属性和方法能被包内及包外子类访问。注意,即时并非继承关系,protected属性和方法在同一包内也是可见的。
• 无:
即无任何访问权限控制符,注意这不能说成default,它并非访问权限控制符的关键字,另外在JDK8接口中引入default默认方法实现,更加容易混淆两者释义。无访问权限控制符仅对包内可见。虽然无访问权限控制符还可以修饰外部类,但是定义外部类极少使用无控制符的方式,要么定义为内部类,功能内聚;要么定义为公开类,即public class,包外也可以实例化。
• private:
只能修饰属性、方法和内部类,表示“私有的”,是访问限制最严格的一级,被其修饰的属性或方法只能在该类内部访问,子类、包内均不能访问,更不允许跨包访问。
由此可见,不同的访问权限控制符对应的可见范围不同。在定义类时,要慎重思考该方法、属性、内部类的访问权限,提供严控访问范围。过于宽泛的访问范围不利于模块间解耦及未来的代码维护。在定义类时,推荐访问控制级别从严处理:
(1)如果不允许外部直接通过new创建对象,构造方法必须是private。
(2) 工具类不允许有public或default构造方法。
(3)类非static成员变量并且与子类共享,必须是protected。
(4)类非static成员变量并且仅在本类使用,必须是private。
(5)类static成员变量如果仅在本类使用,必须是private。
(6)若是static成员变量,必须考虑是否为final。
(7)类成员方法只供类内部调用,必须是private。
(8)类成员方法只对继承类公开,那么限制为protected。
3.5 this与super
对象实例化时,至少有一条从本类出发抵达Object的通路,而打通这条路的两个主要工兵就是this和super,但二者往往是默默无闻的,在很多情况下都可以省略,比如:
• 本类方法调用本类属性。
• 本类方法调用另一个本类方法。
• 子类构造方法隐含调用super()。
任何类在创建之初,都有一个默认的空构造方法,它是super()的一条默认通路。构造方法的参数列表决定了调用通路的选择;如果子类指定调用父类的某个构造方法,super就会不断往上溯源;如果没有指定则默认调用super()。注意,如果父类没有提供默认的构造方法,子类在继承时就会发生编译出错。如果父类坚持不提供默认的无参构造方法,则必须在子类的无参构造方法中使用super方式调用父类的有参构造方法,如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 父类的定义
class Father {
// 父类不提供无参的构造函数
// public Father() {}
// 仅有有参的构造函数
public Father(String name) {}
}
// 子类的定义
class Son extends Father {
// 使用super调用父类的有参构造方法
public Son() {
super("test");
}
}
一个实例变量可以通过this.赋值另一个实例变量,一个实例方法可以通过this.调用另一个实例方法,甚至一个构造方法都可以通过this.调用另一个构造方法。在一个构造方法中,this和super只能出现一个,且只能出现一次,否则在实例化对象时,会因子类调用到多个父类构造方法而造成混乱。
由于this和super都在实例化阶段调用,所以不能在静态方法和静态代码块中使用。this还可以指代当前对象,比如在同步代码块synchronized(this){...}中,super则在子类覆写父类方法时,用来调用父类同名的实例方法。二者的异同点如下表所示:
| 基本概念 | 查找范围 | 特异功能 | 共同点 | |
|---|---|---|---|---|
| this | 访问本类实例属性和方法 | 先找本类,没有则找父类 | 单独使用时,表示当前对象 | 都是指代作用,在构造方法中必须出现在第一行 |
| super | 由子类访问父类中的实例属性和方法 | 直接查找父类 | 在子类覆写父类方法时,访问父类同名方法 | 都是指代作用,在构造方法中必须出现在第一行 |
3.6 类关系
类与类之间的关系主要分为两种,即有关系和没关系,难点在于确认类与类之间是否存在相互作用,证明类之间没关系是一个涉及业务、架构、模块边界的问题,往往由于业务模型的抽象角度不同而不同。如果找到了没有关系的点,那么就可以进行架构隔离、模块解耦等工作。对于有关系的情况,包括以下6种类型:
• 【继承】extends(is-a)。
• 【实现】implements(can-do)。
• 【组合】类是成员变量(contains-a)。
• 【聚合】类是成员变量(has-a)。
• 【依赖】是除组合与聚合外的单向弱关系(depends-a)。
• 【关联】是互相平等的依赖关系(links-a)。
继承和实现是比较容易理解的两种关系,在架构设计中,需要注意组合、聚合、依赖和关联这四个的区别:
(1)组合在汉语中的含义是把若干个独立部分组成整体,各个部分都有其独立的使用价值和生命周期。而类关系中的组合体现的是一种完全绑定的关系,所有成员共同完成一件使命,它们的生命周期是一样的。组合体现的是非常强的整体与部分的关系,同生共死,部分不能在整体之间共享。
(2)聚合是一种可以拆分的整体与部分的关系,是非常松散的暂时组合,部分可以被拆出来给另一个整体,比如汽车与轮子之间的关系就是聚合关系。
(3)依赖是除组合和聚合外的类与类之间的单向弱关系,使用另一个类的属性、方法,或以其作为方法的参数输入,或以其作为方法的返回值输出。依赖往往是模块解耦的最佳点。
(4)关联即是相互平等的依赖关系,可以在关联点上进行解耦,但是解耦难度略大于依赖关系。
在类图中,用空心的三角形表示继承,用实心的菱形表示组合,用空心的菱形表示聚合,用一条直线表示关联,这四者都是用实线连接的;用三角形表示实现,用一个箭头表示依赖,这两者是用虚线连接的。
| 类关系 | 英文名 | 描述 | 权力强侧 | 类图示例 | 示例说明 |
|---|---|---|---|---|---|
| 继承 | Generalization | 父类与子类之间的关系:is-a | 父类方 | 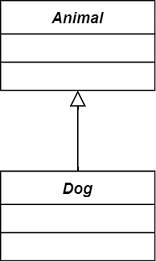 |
小狗继承于动物,完全符合里氏代换原则 |
| 实现 | Realization | 接口与实现类之间的关系:can-do | 接口方 | 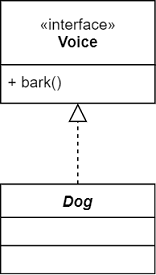 |
小狗实现了狗叫的接口行为 |
| 组合 | Composition | 比聚合更强的关系:contains-a | 整体方 | 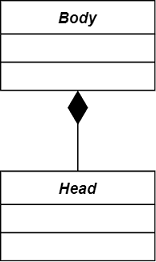 |
头只能是身体强组合的一部分,两者完全不可分,具有相同的生命周期 |
| 聚合 | Aggregation | 暂时组装的关系:has-a | 组装方 | 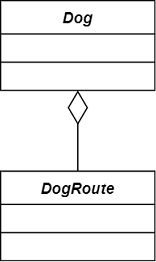 |
小狗与狗绳之间是暂时聚合关系,狗绳完全可以复用在另一条小狗上 |
| 依赖 | Dependency | 一个类用到另一个类:depends-a | 被依赖方 | 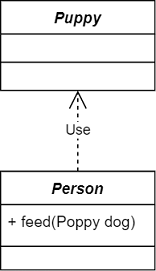 |
人喂养小狗,小狗作为参数传入,是依赖关系 |
| 关联 | Association | 类与类之间存在互相平等的关系:links-a | 平等 | 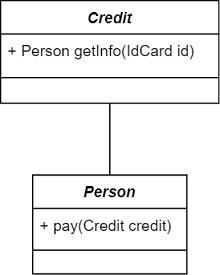 |
人可以用信用卡消费,信用卡可以提取到人的信息 |
3.7 序列化
内存中的数据对象只有转换为二进制流才可以进行数据持久化和网络传输,因此将数据对象转换为二进制流的过程称为对象的序列化(Serialization),反之将二进制流恢复为数据对象的过程称为反序列化(Deserialization)。序列化常见的使用场景是RPC框架的数据传输,常见的序列化方式有以下三种:Java原生序列化、Hessian序列化、JSON序列化。
3.7.1 Java原生序列化
Java类通过实现Serializable接口来实现该类对象的序列化,这个接口非常特殊,没有任何方法,只起标识作用。Java序列化保留了对象类的元数据(如类、成员变量、继承类信息等),以及对象数据等,兼容性最好,但不支持跨语言,而且性能一般。
实现Serializable接口的类建议设置serialVersionUID字段值,如果不设置,那么每次运行时编译器会根据类的内部实现,包括类名、接口名、方法和属性等来自动生成serialVersionUID。如果类的源代码有修改,那么重新编译后serialVersionUID的取值可能发生变化,因此一定要显式地定义serialVersionUID属性值。
使用Java原生序列化需注意,Java反序列化时不会调用类的无参构造方法,而是调用native方法将成员变量赋值为对应类型的初始值。基于性能以及兼容性考虑,不推荐使用Java原生序列化。
3.7.2 Hessian序列化
Hessian序列化是一种支持动态类型、跨语言、基于对象传输的网络协议,Java对象序列化的二进制流可以被其他语言(如C++、Python)反序列化。Hessian序列化具有如下的特性:
• 自描述序列化类型。不依赖外部描述文件或接口定义,用一个字节表示常用基础类型,极大缩短二进制流。
• 语言无关,支持脚本语言。
• 协议简单,比Java原生序列化高效。
相比Hessian 1.0,Hessian 2.0中增加了压缩编码,其序列化二进制流大小是Java序列化的50%,序列化耗时是Java序列化的30%,反序列化耗时是Java反序列化的20%。Hessian会把复杂对象所有属性存储到一个Map中进行序列化,在父类、子类存在同名成员变量的情况下,Hessian序列化时会先序列化子类,然后序列化父类,因此反序列化时会导致子类同名成员变量被父类的值覆盖。
3.7.3 JSON序列化
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。JSON序列化就是将数据对象转换为JSON字符串,在序列化过程中抛弃了类型信息,所以反序列化时只有提供类型信息才能准确地反序列化。相比前两种方式,JSON可读性比较好,方便调试。
序列化通常会通过网络传输对象,而对象中往往有敏感数据,所以序列化常常称为黑客的攻击点,攻击者巧妙地利用反序列化过程构造恶意代码,使得程序在反序列化的过程中执行任意代码。为了防范黑客的攻击,对于不需要进行序列化传输的敏感属性,可以加上transient关键字,避免把此属性信息转换为二进制流。如果一定要传递对象的敏感属性,可以使用对称与非对称加密方式独立传输,再使用某个方法把属性还原到对象中。
4. 方法
4.1 方法签名
方法签名包括方法名称和参数列表,是JVM标识方法的唯一索引,不包括返回值,更加不包括访问权限控制符、异常类型等。假如返回值可以是方法签名的一部分,仅从代码可读性角度来考虑,比如下面的例子:1
2
3
4
5
6
7
8
9long f() {
return 1L;
}
double f() {
return 1.0d;
}
var a = f();
那么类型推断的var到底是接收1.0d还是1L?从静态阅读的角度,根本无从知道它调用的是那个方法。
4.2 参数
参数在方法中,属于方法签名的一部分,包括参数类型和参数个数,多个参数用逗号相隔,在代码风格中,约定每个逗号后必须要有一个空格,不管是形参,还是实参。形参是在方法定义阶段,而实参是在方法调用阶段,下面通过一个例子来看看实参传递给形参的过程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60public class ParamPassing {
private static int intStatic = 111;
private static String stringStatic = "old string";
private static StringBuilder stringBuilderStatic = new StringBuilder("old stringBuilder");
// A方法
public static void method() {
intStatic = 222;
}
// B方法
public static void method(int intStatic) {
intStatic = 333;
}
// C方法
public static void method(String stringStatic) {
stringStatic = "new string";
}
// D方法
public static void method(StringBuilder stringBuilderStatic1, StringBuilder stringBuilderStatic2) {
// 直接使用参数引用修改对象
stringBuilderStatic1.append(".method.first-");
stringBuilderStatic2.append("method.second-");
// 引用重新赋值
stringBuilderStatic1 = new StringBuilder("new stringBuilder");
stringBuilderStatic1.append("new method's append");
}
// 实参调用例子
public static void main(String[] args) {
method(intStatic);
/**
* 调用B方法,参数intStatic是局部变量,根据作用域就近原则,
* 对其的所有操作都与静态变量无关,所以最后的输出为:111
*/
System.out.println(intStatic);
method();
/**
* 调用A方法,无参数,修改的就是静态变量,所以最后的输出为:222
*/
System.out.println(intStatic);
method(stringStatic);
/**
* 调用C方法,参数stringStatic也是局部变量,所以最后的输出为:old string
*/
System.out.println(stringStatic);
method(stringBuilderStatic, stringBuilderStatic);
/**
* 调用D方法,前面对StringBuilder对象引用变量的修改就是修改静态变量,
* 而后面new的StringBuilder对象是新的局部变量,后续操作就与之前的静态变量无关,
* 所以最后的输出为:old string.method.first-method.second-
*/
System.out.println(stringBuilderStatic);
}
}
从上面的例子中可以得知,无论是对于基本数据类型,还是引用变量,Java中的参数传递都是值复制的传递过程。对于引用变量,复制指向对象的首地址,双方都可以通过自己的引用变量修改指向对象的相关属性。
下面介绍一种特殊的参数——可变参数。它在JDK5版本中引入的,主要为了解决当时的反射机制和printf方法问题,适用于不确定参数个数的场景。可变参数通过“参数类型...”的方式定义,如下所示的PrintStream类中的printf方法:1
2
3
4
5
6
7public PrintStream printf(String format, Object... args) {
return format(format, args);
}
// 调用printf方法示例
System.out.println("%d", n);
System.out.println("%d %s", n, "test");
在实际开发过程中,尽量不要使用可变参数编程,如果使用不当会严重影响代码的可读性和可维护性。如果一定要使用,则只有相同参数类型,相同业务含义的参数才可以,并且一个方法中只能有一个可变参数,且可变参数必须是该方法的最后一个参数。此外,建议不要使用Object作为可变参数,因为其容易破坏“可变参数具备相同类型,相同业务含义”这个大前提。比如下面的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public static void listItems(Object... args) {
System.out.println(arg.length);
}
public static void main(String[] args) {
// 输出结果为3
listItems(1, 2, 3);
// int[]只能当成一个Object对象,故输出结果为1
listItems(new int[] {1, 2, 3});
// 输出结果为2
listItems(3, new String[] {"1", "2"});
// 这里Integer[]会转型为Object[],故输出结果为3
listItems(new Integer[] {1, 2, 3});
// 这里Integer[]被当成一个Object对象,故输出结果为2
listItems(3, new Integer[] {1, 2, 3});
}
在实际中,方法定义方并不能保证调用方会按照预期传入参数,因此在方法体中应该对传入的参数保持理性的不信任。方法的第一步骤不是功能实现,而应该是参数预处理。参数预处理包括以下两种方式:
(1)入参保护
入参保护实质上是对服务提供方的保护,常见于批量接口。批量接口是指能同时处理一批数据,但其处理能力并不是无限的,因此需要对入参的数据量进行判断和控制,如果超出处理能力,可以直接返回错误给客户端。
(2)参数校验
参数作为方法间交互和传递信息的媒介,其重要性不言而喻,因此对参数有效值的检测都是非常有必要的。由于方法间交互是非常频繁的,如果所有方法都进行参数校验,就会导致重复代码以及不必要的检查影响代码性能。综合这两个方面考虑,需要进行参数校验和无须校验的场景如下表所示:
| 类型 | 使用场景 |
|---|---|
| 参数校验 | 1.调用频度低的方法。 2.执行时间开销大的方法。 3.需要极高稳定性和可用性的方法。 4.对外提供的开放接口。 5.敏感权限入口。 |
| 无须校验 | 1.极有可能被循环调用的方法,但在方法外部应该进行参数检查。 2.底层调用频度较高的方法,因为参数错误不太可能到底层才暴露问题。 3.声明成private且只会被自己代码调用的方法。 |
4.3 构造方法
构造方法(Constructor)是方法名与类名相同的特殊方法,在新建对象时调用,可以通过不同的构造方法实现不同方式的对象初始化,它有以下几个特征:
(1)构造方法名称必须与类名相同。
(2)构造方法是没有返回类型的,即时是void也不能有。它返回对象的地址,并赋值给引用变量。
(3)构造方法不能被继承,不能被覆写,不能被直接调用。调用的途径有三种:一是通过new关键字,二是在子类的构造方法中通过super调用父类的构造方法,三是通过反射方式获取并使用。
(4)类定义时提供了默认的无参构造方法。但是如果显式定义了有参构造方法,则此无参构造方法就会被覆盖;如果依然想拥有,就需要进行显式定义无参构造方法。
(5)构造方法可以私有。但是外部无法使用私有的构造方法创建对象。
在接口中不能定义构造方法,在抽象类中可以定义。在枚举类中,构造方法是特殊的存在,它可以定义,但不能加public修饰,因为它默认是private的,是绝对的单例,不允许外部以创建对象的方式生成枚举对象。
单一职责,对于构造方法同样适用,构造方法的使命就是在构造对象时进行传参操作,所以不应该在构造方法中引入业务逻辑。如果一个对象生产中,需要完成初始化上下游对象、分配内存、执行静态方法、赋值句柄等繁重的工作,其中某个步骤出错,导致没有完成对象的初始化,再将希望寄托于业务逻辑部分来处理异常就是一件不受控制的事情了。
类中的static {...}代码块被称为类的静态代码块,在类的初始化执行,优先级很高。下面通过一个实际的例子来看父类和子类的静态代码块和构造方法的执行顺序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// 父类定义
class Parent {
static {
System.out.println("Parent's static code block!");
}
Parent() {
System.out.println("Parent's Constructor!");
}
}
// 子类定义
class Son extends Parent {
static {
System.out.println("Son's static code block!");
}
Son() {
System.out.println("Son's Constructor!");
}
public static void main(String[] args) {
new Son();
new Son();
}
}
/**
* 上面的代码输出结果如下:
* Parent's static code block!
* Son's static code block!
* Parent's Constructor!
* Son's Constructor!
* Parent's Constructor!
* Son's Constructor!
*/
从上面的示例可以看出,在创建类对象时,会先执行父类和子类的静态代码块,再执行父类和子类的构造方法,而且静态代码块只会运行一次,在第二次对象实例化时,就不会运行了。
4.4 类内方法
在面向过程的语言中,几乎所有的方法都是全局静态方法,在引入面向对象理念之后,某些方法才归属于具体对象,即类内方法。构造方法无论是有形还是无形,无论私有还是公有,在一个类中是必然存在的。除构造方法外,类中还有三类方法:实例方法、静态方法、静态代码块。
4.4.1 实例方法
实例方法又称为非静态方法,其比较简单,必须依附于某个实际对象,并可以通过引用变量调用其方法。类内部各个实例方法之间可以相互调用,也可以直接读写类内变量,但是不包含this。当.class字节码文件加载之后,实例方法并不会被分配方法入口地址,只有在对象创建之后才会被分配。实例方法可以调用静态变量和静态方法,当从外部创建对象后,应尽量使用“类名.静态方法”来调用,而不是对象名,一来为编译器减负,二来提升代码可读性。
4.4.2 静态方法
静态方法又称为类方法(属于整个类),当类加载后,即分配了相应的内存空间,由于生命周期的限制,使用静态方法需要注意两点:
(1)静态方法中不能使用实例成员变量和实例方法。
(2)静态方法不能使用super和this关键字,这两个关键字指代的都是需要被创建出来的对象。
通常静态方法用于定义工具类的方法等,静态方法如果使用了可修改的对象,那么在并发时会存在线程安全问题。所以,工具类的静态方法与单例通常是相伴而生的。
4.4.3 静态代码块
在代码的执行方法体中,非静态代码块和静态代码块比较特殊。非静态代码块又称为局部代码块,是极不推荐的处理方式,这里不再展开。而静态代码块在类加载的时候就被调用,并且只执行一次。静态代码块是先于构造方法执行的特殊代码块。静态代码块不能存在于任何方法体内,包括类静态方法和属性变量。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class StaticCode {
// prior必须定义在last之前,否则编译会出错
static String prior = "done";
// 依次调用f()的结果,三目运算符为true,执行g(),最后赋值
static String last = f() ? g() : prior;
public static boolean f() {
return true;
}
public static String g() {
return "hello world";
}
static {
// 静态代码块可以访问静态变量和静态方法
System.out.println(last);
g();
}
}
在上述代码中,由于变量last依赖了变量prior,所以两者直接存在先后关系,而静态方法与静态变量之间没有先后关系。在实际应用中例如容器初始化时,可以使用静态代码块实现类加载判断、属性初始化、环境配置等。很多容器框架会在单例对象初始化成功后调用默认init()方法,完成例如RPC注册中心服务器判断、应用通用底层数据初始化等动作。
4.5 getter与setter
在实例方法中,有一类特殊的方法,即getter和setter方法,它们一般不包含任何业务逻辑,仅仅是为类成员属性提供读取和修改的方法,这样设计有两点好处:
(1)满足面向对象语言封装的特性。尽可能将类中的属性定义为private,针对属性值的访问与修改需要使用相应的getter和setter方法,而不是直接对public的属性进行读取和修改。
(2)有利于统一控制。实际业务要求对某个属性值的修改要增加统一的权限控制,如果有setter作为统一的属性修改方法则更容易实现,这种情况在一些使用反射的框架中作用尤其明显。
最典型的getter和setter方法使用时在POJO(Plain Ordinary Java Object,简单的Java对象)类中,常见的POJO类包括DO(Data Object)、BO(Business Object)、DTO(Data Transfer Object)、VO(View Object)、AO(Application Object)。POJO作为数据载体,通常用于数据传输,不应该包含任何业务逻辑。下面来看一个简单的示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class TicketDO {
private Long id;
// 目的地
private String destination;
// getter方法,只需直接返回相应的属性值
public Long getId() {
return id;
}
public String getDestination() {
return destination;
}
// setter方法,如果参数名与成员变量名一致,则使用:this.成员变量名 = 参数名
public void setId(Long id) {
this.id = id;
}
public void setDestination(String destination) {
this.destination = destination;
}
}
4.6 同步与异步
同步调用是刚性调用,是阻塞式操作,必须等待调用方法体执行结束。而异步调用是柔性调用,是非阻塞式操作,在执行过程中,如调用其他方法,自己可以继续执行而不被阻塞等待方法调用完毕。异步调用通常用在某些耗时长的操作上,这个耗时方法的返回结果,可以使用某种机制反向通知,或者再启动一个线程轮询。反向通知方式需要异步系统和各个调用它的系统进行耦合;而轮询对于没有执行完成的任务会不断请求,从而加大执行及其的压力。
异步处理的任务是非时间敏感的。比如,在连接池中,异步任务会定期回收空闲线程。举个现实的例子,在代码管理平台中,提交代码的操作是同步调用,需要实时返回给用户结果。但是当前库的代码相关活动记录不是时间敏感的,在提交代码时,发送一个消息到后台的缓存队列中,后台服务器定时消费这些消息即可。
4.7 覆写(Override,重写)
如果父类定义的方法达不到子类的期望,那么子类可以重新实现方法覆盖父类的实现,这就是覆写。因为有些子类是延迟加载的,甚至是网络加载的,所以最终的实现需要在运行期判断,这就是所谓的动态绑定。动态绑定是多态性得以实现的重要因素,元空间有一个方法表保存着每个可以实例化类的方法信息,JVM可以通过方法表快速地激活实例方法。如果某个类覆写了父类的某个方法,则方法表中的方法指向引用会指向子类的实现处。通常是用父类对象引用来调用子类覆写的方法,也就是常说的向上转型,例子如下:1
2
3Father father = new Son();
// 调用Son覆写了的方法
father.doSomething();
向上转型时,通过父类引用执行子类方法时需要注意一下两点:
• 无法调用到子类中存在而父类本身不存在的方法。
• 可以调用到子类中覆写了父类的方法,这是一种多态实现。
想成功地覆写父类方法,需要满足下面的4个条件:
(1)访问权限不能变小。访问权限变小意味着在调用时父类的可见方法无法被子类多态执行,也就是说,如果父类中方法是用public修饰的,则子类覆写时不能使用private或protected。
(2)返回类型能够向上转型成为父类的返回类型。虽然方法返回值不是方法签名的一部分,但是在覆写时,父类的方法表指向了子类实现方法,编译器会检查返回值是否向上兼容。换句话说,子类的返回类型要和父类的返回类型相同,或者子类的返回类型是父类的返回类型的派生类。
(3)异常也要能向上转型成为父类的异常。异常分为checked和unchecked两种类型,如果父类抛出一个checked类型,则子类只能抛出此异常或此异常的子类。而unchecked异常不用显式地向上抛出,所以没有任何兼容问题。
(4)方法名、参数类型及个数必须严格一致。所有的覆写方法必须加上@Override注解,,此时编译器会自动检查覆写方法前面是否一致,避免了覆写时因写错方法名或方法参数而导致覆写失败。此外,@Override注解还可以避免因权限控制可见范围导致的覆写失败。
综上所述,方法的覆写可以总结成容易记忆的口诀:“一大两小两同”。
• 一大:子类的方法访问权限控制符只能相同或变大。
• 两小:抛出异常和返回值只能相同或变小,能够转型成父类对象。
• 两同:方法名和参数必须完全相同。
还需要注意的是,覆写只能针对非静态、非final、非构造方法。补充一点,隐藏是针对成员变量和静态方法而言的。当子类声明与父类中同名的成员变量时,则实现了对父类中成员变量的隐藏;当子类声明了与父类中同名的静态方法(参数和返回值也要相同),则实现了对父类中静态方法的隐藏。
5. 重载(Overload)
在同一个类中,如果多个方法有相同的方法名、不同的参数类型、参数个数、参数顺序,即称为重载,比如一个类中有多个构造方法。但是需要注意,方法返回值并非是这个组合体中的一员,所以在使用重载时,不能有两个方法名称、参数类型和参数个数完全相同,但是返回类型不同的方法,否则会编译出错(访问控制符、静态标识符和final标识符都不是方法签名的一部分,也同理)。下面来看一个重载的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public class OverloadMethods {
// 第一种:无参方法
public void methodForOverload() {
System.out.println("无参方法");
}
// 第二种:基本数据类型
public void methodForOverload(int param) {
System.out.println("参数为基本类型int的方法");
}
// 第三种:包装数据类型
public void methodForOverload(Integer param) {
System.out.println("参数为包装类型Integer的方法");
}
// 第四种:可变参数,可接受0~n个Integer对象
public void methodForOverload(Integer... param) {
System.out.println("可变参数方法");
}
// 第五种:Object对象
public void methodForOverload(Object param) {
System.out.println("参数为Object的方法");
}
public static void main(String[] args) {
OverloadMethods overloadMethods = new OverloadMethods();
overloadMethods.methodForOverload(7);
}
}
在上面的代码中,main方法中调用了methodForOverload(7),但究竟会执行哪个方法呢?这就要看JVM在重载方法中,选择合适的目标方法的顺序:
(1)精确匹配。
(2)如果是基本数据类型,自动转换成更大表示范围的基本类型。比如int->long。
(3)通过自动拆箱与装箱。比如int->Integer。
(4)通过子类向上转型继承路线依次匹配。比如Integer->Object。
(5)通过可变参数匹配。
显然,精确匹配优先,int和Integer比较会胜出,因为不需要自动装箱,所以调用methodForOverload(7)会执行第二种方法。但如果是new Integer(7),因为不需要自动拆箱,就会执行第三种方法。
父类的公有实例方法与子类的公有实例方法可以存在重载关系,不管继承关系如何复杂,重载在编译时可以根据规则知道调用哪种目标方法,因此重载又称为静态绑定。
6. 泛型
泛型的本质时类型参数化,解决不确定具体对象类型的问题。在面向对象编程语言中,允许程序员在强类型校验下定义某些可变部分,以达到代码服用的目的。Java在引入泛型钱,表示可变类型,往往存在类型安全的风险。举一个生活中的例子,微波炉最主要的功能是加热食物,即加热肉、加热汤都有可能。在没有泛型的场景中,往往会写出如下代码:1
2
3
4
5
6
7
8
9
10
11
12
13class Stove {
public static Object heat(Object food) {
System.out.println(food + " is done!");
return food;
}
public static void main(String[] args) {
Meat meat = new Meat();
meat = (Meat)Stove.heat(meat);
Soup soup = new Soup();
soup = (Soup)Stove.heat(soup);
}
}
为了避免给每种食材定义一个加热方法,如heatMeat()、heatSoup()等,将heat()的参数和返回值定义为Object,用“向上转型”的方式,让其具备可以加热任意类型对象的能力。这种方式增强了类的灵活性,但是客户端对加热的内容一无所知,在取出来强制转换时就会存在类型转换风险。而泛型则可以完美地解决这个问题。
泛型可以定义在类、接口、方法中,编译器通过识别尖括号和尖括号内的字母来解析泛型。在泛型定义时,约定俗成的符号包括:E代表Element,用于集合中的元素;T代表the Type of object,表示某个类;K代表Key、V代表Value,用于键值对元素。关于泛型需要注意以下几点:
(1)尖括号里的每个元素都指代一种未知类型。比如String出现在尖括号中,它就不是java.lang.String,而仅仅是一个代号。
(2)尖括号的位置非常讲究,必须在类名之后或方法返回值之前。
(3)泛型在定义处只具备执行Object方法的能力。即泛型只能调用Object类中的方法,如toString()。
(4)对于编译之后的字节码指令,其实没有这些花头花脑的方法签名,充分说明了泛型只是一种编写代码时的语法检查。在使用泛型元素时,会执行强制类型转换,这就是类型擦除。
泛型只是在编译期增加了一道检查而已,目的是促使程序员在使用泛型时安全放置和使用数据,总的来说具有以下几个好处:
• 类型安全。放置的是什么,取出来的自然是什么,不用担心抛出ClassCastException异常。
• 提升可读性。从编码阶段就显式地知道泛型集合、泛型方法等处理的对象是什么。
• 代码复用。泛型合并了同类型的处理代码,使代码重用度变高。
再回到前面的微波炉加热食物的例子,使用泛型可以很好地实现,示例代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14class Stove {
public static <T> heat(T food) {
System.out.println(food + " is done!");
return food;
}
public static void main(String[] args) {
Meat meat = new Meat();
meat = Stove.heat(meat);
Soup soup = new Soup();
soup = Stove.heat(soup);
}
}
7. 数据类型
7.1 基本数据类型
虽然Java是面向对象编程语言,一切皆是对象,但是为了加快常规数据的处理速度,提供了9种基本数据类型,它们都不具备对象的特性,没有属性和行为。基本数据类型是指不可再分的原子数据类型,内存中直接存储此类型的值,通过内存地址即可访问到数据,并且此内存区域只能存放基本数据类型。Java的9种基本数据类型包括boolean、byte、char、short、int、long、float、double和refvar。前8种数据类型表示生活中的真假、字符、整数和小数,最后一种refvar是面向对象世界中的引用变量,也叫引用句柄。前8种都有对应的包装数据类型,它们的默认值、空间占用大小、表示范围等信息如下表所示:
| 类型 | 默认值 | 大小 | 最小值 | 最大值 | 包装类 | 缓存区间 |
|---|---|---|---|---|---|---|
| boolean | false | 1B | 0(false) | 1(true) | Boolean | 无 |
| byte | (byte)0 | 1B | -128 | 127 | Byte | -128~127 |
| char | ‘\u0000’ | 2B | ‘\u0000’ | ‘\uFFFF’ | Character | (char)0~(char)127 |
| short | (short)0 | 2B | -215 | 215-1 | Short | -128~127 |
| int | 0 | 4B | -231 | 231-1 | Integer | -128~127 |
| long | 0L | 8B | -263 | 263-1 | Long | -128~127 |
| float | 0.0f | 4B | 1.4e-45 | 3.4e+38 | Float | 无 |
| double | 0.0d | 8B | 4.9e-324 | 1.798e+308 | Double | 无 |
引用分成两种数据类型:引用变量本身和引用指向的对象。通常为了区分二者,将引用变量(Reference Variable)称为refvar,将引用指向的实际对象(Referred Object)称为refobj。refvar类似基本变量,默认值是null,存储refobj的首地址,可以直接使用==进行等值判断,占4B空间。需要注意的是refobj对象最小占用的存储空间是12B(用于存储基本信息,即对象头),但是由于存储空间分配必须是8B的倍数,所以初始分配的空间至少是16B。
一个refvar至多存储一个refobj的首地址,一个refobj可以被多个refvar存储下它的首地址,即一个堆内对象可以被多个refvar引用指向。如果refobj没有被任何refvar指向,那么它迟早会被垃圾回收,而refvar的内存释放,与其他基本数据类型类似。
7.2 包装类型
前8种基本数据类型都有相应的包装类,包装类的存在解决了基本数据类型无法做到的事情:泛型类型参数、序列化、类型转换、高频区间数据缓存。除了Float和Double外,其他包装数据类型都会缓存,包装类直接赋值时就是调用相应的静态工厂方法valueOf()(如果赋值数据在缓存区间内)。在JDK9中直接把new的构造方法过时,推荐使用valueOf(),合理利用缓存,提升程序性能。各个包装类的缓存区间在7.1章节中已经提到,在选择使用包装类还是基本数据类型时,推荐使用如下的方式:
(1)所有的POJO类属性必须使用包装数据类型。
(2)RPC方法的返回值和参数必须使用包装类型。
(3)所有的局部变量推荐使用基本数据类型。
7.3 字符串
字符串类型是常用的数据类型,字符串相关类型主要有3种:String、StringBuffer、StringBuilder。String是只读字符串,典型的immutable对象,对它的任何改动,其实都是创建一个新对象,再把引用指向该对象。String对象赋值操作后,会在常量池中进行缓存,如果下次申请创建对象时,缓存中已经存在,则直接返回相应的引用给创建者。而StringBuffer可以在原对象上进行修改,是线程安全的。StringBuilder也可以在原对象上进行修改,但是非线程安全的,它把是否需要进行多线程加锁交给工程师决定,操作效率比StringBuffer高。
在非基本数据类型的对象中,String是仅支持直接相加操作的对象。这样操作虽然比较方便,但在循环体中,字符串的拼接方式应该使用StringBuilder的append方法,否则性能会很差。
...
...